本記事では、Neural Voice Puppetryと呼ばれる機械学習手法を使って顔写真から3Dアバターを作成し、喋らせる方法を紹介します。

style_avatarとは
Neural Voice Puppetryは、オーディオを起点とした顔のビデオ生成手法です。
顔写真とオーディオを入力すると、オーディオに同期した顔写真の3Dアバターを生成し写実的なビデオを出力します
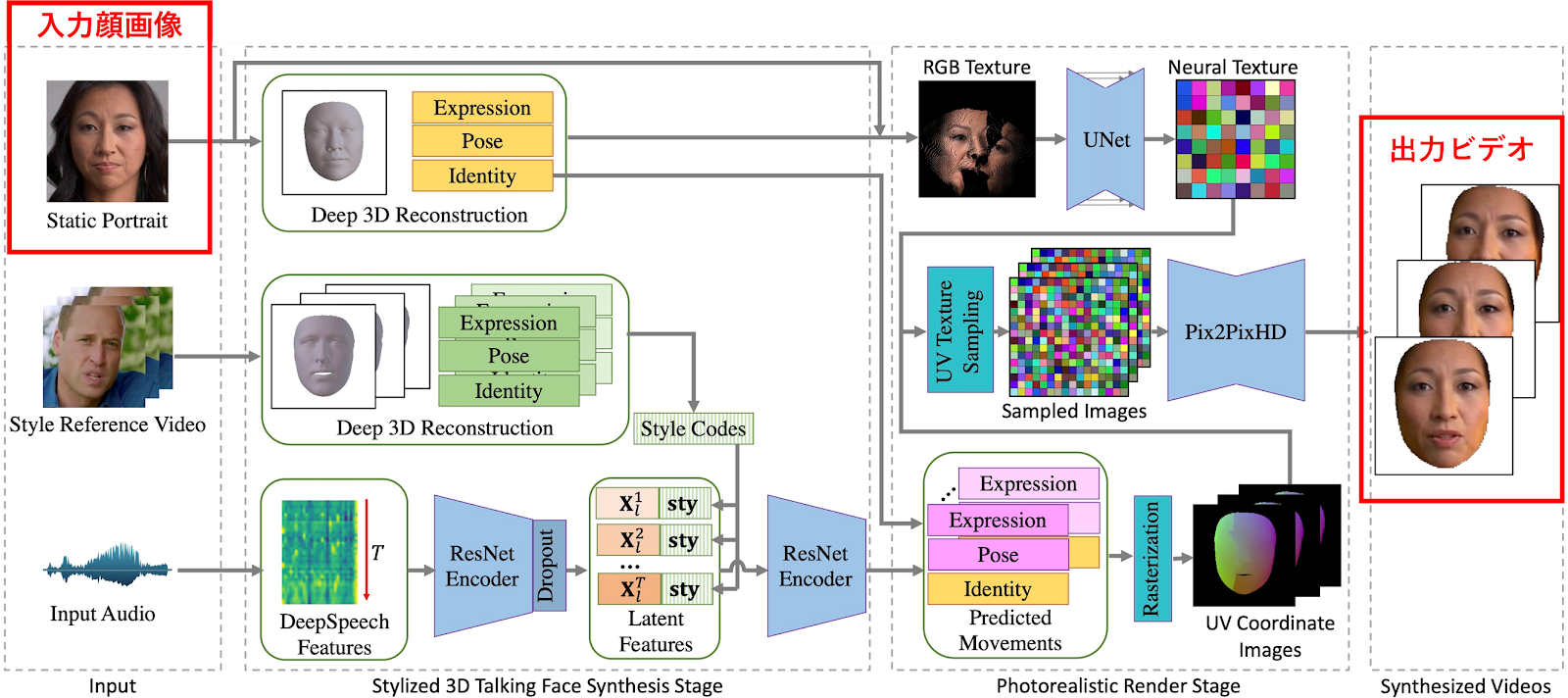
|
| 出典: https://github.com/wuhaozhe/style_avatar |
この技術によって、合成音声で生成したオーディオから特定の俳優が話す動画を生成することができます。
こちらに公式のデモ動画がアップデートされています。デモ動画
使用ユースケースとしては、下記が挙げられています。
- オーディオ起点のアバター生成
- ビデオの生成
- 肩から上の大写し映像の生成
この技術は、現実の撮影なくあたかもその人が話したかのような動画を生成できます。
悪用すれば悪質なFake動画を生成できてしまいます。
このため、法律を遵守し、倫理観に反さない使用が求められます。
Neural Voice Puppetryの導入手順
セットアップ
それでは早速、開発環境にNeural Voice Puppetryをセットアップしていきます。
動作確認は下記の環境で行っています。
OS: Ubuntu 18.04.3 LTS
GPU: GeForce GTX 1080
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
それでは、Neural Voice Puppetryをインストールしていきます。
他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
下記のプロジェクトはTensorflow 1.14.0を使用しています。cuda tool kitは10.0である必要があります。
続いてモデルをダウンロードしていきます。
以上で、セットアップは完了です。
アバター生成
入力データには、顔写真と音声データが必要です。
本記事では、ロイヤリティフリーの下記の画像とナレーション音声を利用させて頂きます。

上記のコマンドで--output_pathに--in_imgに指定した顔写真が--in_audioの音声を話す動画が出力されます。
1枚の画像だけで音声に合わせて動くアバターを生成するとはなかなか脅威的です。
便利な一方、正しい使い方が求められますね。
トラブルシューティング集
RuntimeError: The NVIDIA driver on your system is too old
エラー詳細
RuntimeError: The NVIDIA driver on your system is too old (found version
10010). Please update your GPU driver by downloading and installing a new
version from the URL: http://www.nvidia.com/Download/index.aspx
Alternatively, go to: https://pytorch.org to install a PyTorch version that
has been compiled with your version of the CUDA driver.
解決方法
Cannot assign a device for operation Squeeze: node Squeeze
エラー詳細
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign
a device for operation Squeeze: node Squeeze
解決方法
Unknown encoder 'libx264'
エラー詳細
Unknown encoder 'libx264'
解決方法
conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
まとめ
本記事では、Neural Voice Puppetryで一枚の画像から音声に合わせて話すアバターを生成する方法を紹介しました。
このような技術はDeepFakeに代表されるように、耳目を集める技術一方で、誤った使い方をして逮捕者が出ている技術でもあります。
但し、技術に罪がある訳ではなく、技術を使う人に悪意があることが原因だと思います。
是非人の役に使い方をお願い致します。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. 論文 - Neural Voice Puppetry: Audio-driven Facial Reenactment
2. GitHub - wuhaozhe/style_avatar
3. nvidia - CUDA Toolkit 10.0 Archive






0 件のコメント :
コメントを投稿