本記事では、InfoGANと呼ばれる機械学習手法を使って、日本語の手書き文字データを生成する方法を紹介します。

概要
本記事の実施内容の概要説明をはじめに記載します。
本記事では、学習データとして確保が難しい、日本語手書き文字データを自動生成を目指します。
下図は出力のイメージです。
上図のような画像を生成し、AIOCRにおける文字認識の学習データとして活用することを目指します。
技術概要
InfoGAN
InfoGANそのものは、既に素晴らしい日本語の解説記事が存在するためこちらでは説明を割愛します。
【論文メモ:InfoGAN】InfoGAN: Interpretable Representation Learning by
Information Maximizing Generative Adversarial Netsの記事などが参考になるためInfoGANのネットワークの詳細に興味がある方はこちらをご参考下さい。
本記事としては、いくつかの日本語手書き文字データを入力として、様々な日本語手書き文字データを出力するために利用する技術であると理解頂いていれば十分です。
下図は行ごとに変数(continuous latent
variable)を変化させた結果です。行ごとに文字の形状が変化していますね。

|
| 出典: https://github.com/eriklindernoren/PyTorch-GAN#infogan |
ETL文字データベース
ETL文字データベースは、独立行政法人産業技術総合研究所によって収集された、手書きまたは印刷の英数字、記号、ひらがな、カタカナ、教育漢字、JIS第1水準漢字など、
約120万の文字画像データです。
本記事では、これらの内手書きデータを利用させて頂きます。
このデータセットをInfoGANに学習させ、様々な形状の手書き文字を出力するモデルを生成していきます。
InfoGANの導入手順
セットアップ: conda環境構築
それでは早速、開発環境にInfoGANをセットアップしていきます。
動作確認は下記の環境で行っています。
OS: Ubuntu 18.04.3 LTS
GPU: GeForce GTX 1080
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
それでは、InfoGANをインストールしていきます。他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
以上で環境のセットアップは完了です。
手書き数字画像の生成
まず、あらかじめ用意されているinfogan.pyを動かしてみます。
こちらは手書き数字のデータセットであるMNISTを入力とし、様々な形状の手書き数字を出力するモデルをトレーニングします。

|
| 出典: https://github.com/eriklindernoren/PyTorch-GAN#infogan |
上図GIFはepochごとの出力結果を表しています。学習が進むにつれて、徐々に手書き数字のような形状の文字を持つ画像を生成していますね。
日本語の文字画像の生成手順
DataLoaderの定義
これからご紹介するコードは全てこちらのGithubに掲載しています。
本題のETL文字データベースを入力に日本語の手書き文字データの生成を行います。
ETL文字データベースの取得方法は以下の記事はご参照ください。
[AIOCR]手書き日本語OCRデータセットを自動生成する[etlcdb]
まずは、このETL文字データベースをinfoGANに学習させるためDataLoaderを定義します
上記コードの__getitem__を見ていただくとわかりますが、学習時にETLデータベースの画像とその画像のラベルを提供します。
ラベルは従来のinfoGANの実装に合わせて、0~から採番しています。
例えば、"あ"、"い"、"う"、"え"、"お"の画像が存在する場合、
それぞれ"0"、"1"、"2"、"3"、"4"とラベル付けされます。
DataLoaderさえ定義できてしまえば、あとはデータを入力してトレーニングさせるのみです。
ひらがな(10種)画像の生成
まず、MNISTの同じカテゴリ数となるようにあ行と、か行のひらがな10種を学習させてみます。

またlossの推移は以下の通りです。

ひらがな(20種)画像の生成
つづいて、MNISTの同じカテゴリ数となるようにさ行からは行のひらがな20種を学習させてみます。

lossの推移は以下です。

ひらがな(46種)画像の生成
ひらがな全て46種を学習してみます。


カテゴリ数の増加に伴い、正確な形状の画像が生成されにくくなっています。
またinfo lossも高止まりしています。
漢字(10種)画像の生成
さきほどはひらがな全てを一度に学習した場合、カテゴリ数が多くなり学習が上手く収束しない結果となりました。
次に漢字(10種)の学習を行ってみます。
今回用意したデータにおいては、漢字は一文字あたり161枚、ひらがなは一文字あたり700枚と一文字あたりのデータ数に大きな差があります。
同一カテゴリ数のにおける一文字あたりの学習データ数の差による結果の違いを見てみます。

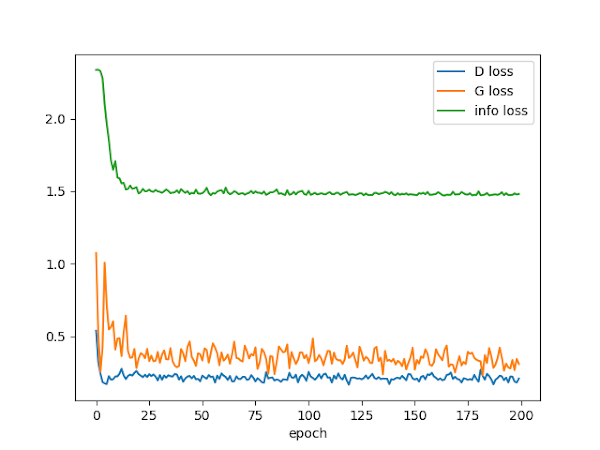
学習データが少ないためか、やや漢字の形状が崩れたままとなりました。
まとめ
本記事では、InfoGANを使って日本語の手書き文字データを自動生成する方法を紹介しました。
学習結果からみると、カテゴリ数は20前後、1文字あたりのデータは700以上は用意しておいた方が良好な出力結果が得られるようです。
現実問題として、モデルの精度確保において、学習データの確保はコストの問題から十分に確保できない場合があります。
今回のように人手をかけずに自動生成する方法があればこれらの課題解決の一つになり得ますね。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。






0 件のコメント :
コメントを投稿