一つ一つ順を追っていきながら機械学習を使った株価予測モデルを作っていきます。
本記事では、Sktimeを使って株価データから重回帰分析を行ってみます。

概要
以下の記事で、時系列データに特化した機械学習ライブラリSktimeの導入、及び、yahoo_finance_api2を用いた日本株データ取得を行いました。 そして、Sktimeで日本株の単回帰分析を行いました。
[sktime] 株価予測AIを作るまで:その① 環境整備、データ準備 [yahoo_finance_api2]
Sktimeの環境整備、yahoo_finance_api2を用いた株価データ取得方法を紹介しています。
[sktime] 株価予測AIを作るまで:その② 単回帰分析
Sktimeを使って日本株の終値を単回帰分析する方法を紹介しています。
本記事では、その続きとして重回帰分析を行っていきたいと思います。
重回帰分析とは
数多の解説記事が存在するため詳細な説明は省きますが、一言でいえば複数の入力変数から 1つの出力変数を予測することです。
今回は、株価の前日の始値、終値、出来高などの複数の入力変数を使って翌日以降の終値を予測してみます。
なお本記事で紹介するソースコードはこちらのGithubに全て載せています
免責事項
本記事は、機械学習、AIの学習を目的としており、投資を薦めるものではありません。
本記事の内容を基に投資を行って生じる、いかなる損失も本記事は一切の責任を負いません。
また、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
データの前処理
今回はyahoo_finance_api2から取得した株価データから、入力変数となる前日の始値、高値、底値、終値、出来高を作成していきます。
はじめに、必要なモジュールをインポートします。
次に、yahoo_finance_api2から取得したデータを整形する関数を定義します。
処理概要はDataFrameに格納し、timestampをUTC時間に変換しています。
任天堂の株価を5年分取得します。

目的変数となるデータを作成します。
先頭行を削除している理由は、前日までのデータを使って翌日以降の終値を予測するため、
取得したデータの初日の終値を予測する前日のデータが存在しないためです。
次に、入力変数となるデータを作成します。
前日までのデータを使って次の日以降の終値を求めるため入力変数を1日ずらします。
データの前処理の最後に学習データとテストデータに分割します。
今回は、データの5%をテストデータとして利用します。
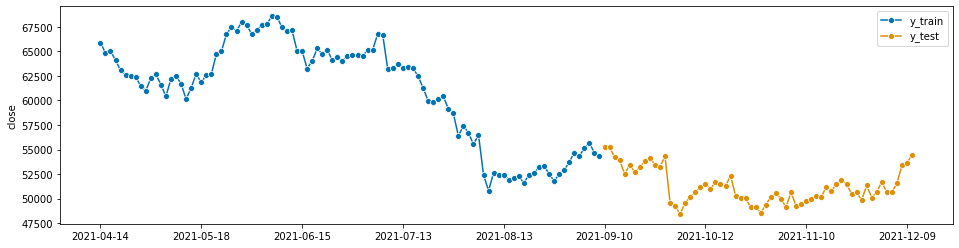
青色で表されている箇所が学習データ、オレンジで表されている箇所がテストデータです。
モデルのトレーニング
今回はProphetを用いてモデルをトレーニングしてみます。
ProphetはFacebookが開発した時系列予測のためのライブラリでありSktimeから利用する事が可能となっています。
stock_close_multiple_regression_prophet.pklが出力されました。
環境にもよりますが、学習自体は1分もたたずに終了しました。
トレーニングによって作成したモデルを使ってテストデータ期間の終値を予測してみたいと思います。
まず、予測期間を示すForecastingHorizonを定義します。
トレーニングしたモデルを使って翌日以降の終値を予測してみます。
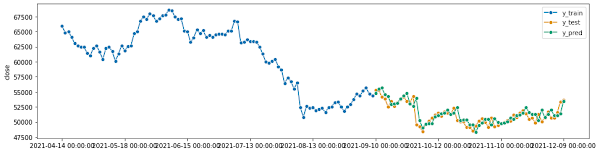
ぱっと見ると予測できていそうですが予測結果がテストデータの1日遅れのコピーのようになっている点が気になります。
モデルが前日の値をそのまま返してしまえば予測値がそれほど外れないことを学習してしまっていそうです。
モデルの評価
最後に生成したモデルの評価を行います。
今回はMAPE(平均絶対パーセント誤差)を用います。ざっくりというと誤差の割合であるため算出結果は少ないほど精度が高いことを示しています。
MAPEの結果は0.014812649413013869となりました。
ちなみにProphetで終値を入力変数に翌日以降の終値を予測する単回帰分析のモデルも生成してみましたが、
こちらの結果はMAPEで0.0198925895059899となったので、やや改善していると言った程度ですね。
入力変数が銘柄単体の指標のみであると、値幅の動きが小さいこともあり有効なモデルとなりにくいかもしれません。
まとめ
本記事では、SktimeでProphetを使用して株価の終値を重回帰分析を実施してみました。
筆者自身勉強中の身であるためご指摘事項等あれば、コメント頂けると幸いです。
また今後は特徴量エンジニアリングに取り組みたいと思います。
合わせてこちらの本なども再度勉強しようと思います。






0 件のコメント :
コメントを投稿