本記事では、Meta(旧
Facebook)が発表したDetic(Detecting Twenty-thousand Classes using Image-level Supervision)を使用して任意の検索キーワードで物体検出を行う方法を紹介します。
Deticとは
概要
Deticとは、2022年にMeta(旧 Facebook)が論文発表したアノテーションフリーの物体検出技術です。
アンカーボックスフリーではありません。アノテーションフリーです。
Deticは、画像分類データセットを使った物体検出器のトレーニングを可能とし物体検出の検出分類数(vocabulary)を大幅に拡張しました。このことにより、Deticは物体検出時にアンカーボックスを用いる必要がなく、実装が簡単になり、且つ、データセットの確保が容易になります。
下記は画像分類のデータセットImageNetの例です。
下記は物体検出のデータセットLVISの例です。
特徴
上図の通り、物体検出のデータセットは、画像中の検出対象物の位置情報を付与する必要があります。
このため画像分類より物体検出のデータセットの確保の方がコストがかかります。
Deticは画像分類のデータセットで物体検出のトレーニングが可能となったため、大量のデータセットから、大量の物体を学習しています。
このことにより、従来よりも多くの様々な物体を検出することができます。
またCLIPを取り込むことで、任意のキーワードに適した物体検出も実現しています。
以下の記事では、有料にはなりますが詳細な技術解説や、実装をご紹介しています。
検出クラスは2万越え! Deticを使って物体を検出しよう
本レシピでは、2022年にMeta(旧Facebook)が発表したDeitcの技術概要、Deticの動かし方などを紹介します。
デモ(Colaboratory)
それでは早速DeticをColaboratoryで動かしてみます。
Pythonで実装していますので、もしPythonの実装に不安がある方は、こちらの書籍などがおすすめです。
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
また以降に記載する実装は全てこちらに掲載しております。
動かす際にはColaboratoryで「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更してください。
それでは動かしていきます。
環境セットアップ
import torch
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
pipでdetectron2をインストールします。
# detectron2をインストール
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/$CUDA_VERSION/torch$TORCH_VERSION/index.html
GitHubからコードをcloneします。
# clone and install Detic
!git clone https://github.com/facebookresearch/Detic.git --recurse-submodules
%cd Detic
!pip install -r requirements.txt
モデルのロード
環境のセットアップが完了したので、モデルをロードします。
今回は、facebookより提供されている学習済みモデルをダウンロードして利用します。
# Build the detector and download our pretrained weights
cfg = get_cfg()
add_centernet_config(cfg)
add_detic_config(cfg)
cfg.merge_from_file("configs/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.yaml")
cfg.MODEL.WEIGHTS = 'https://dl.fbaipublicfiles.com/detic/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.pth'
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
cfg.MODEL.ROI_BOX_HEAD.ZEROSHOT_WEIGHT_PATH = 'rand'
cfg.MODEL.ROI_HEADS.ONE_CLASS_PER_PROPOSAL = True # For better visualization purpose. Set to False for all classes.
predictor = DefaultPredictor(cfg)
物体検出
次に物体検出を行う画像をアップロードします。アップロードするファイルは1枚でも複数枚でも構いません。
from google.colab import files
uploaded = files.upload()
uploaded = list(uploaded.keys())
print(uploaded)
今回はこちらの4画像を入力します。
物体検出を行います。
detect_targetに検出した物体の名称を入力すると、該当の物体を検出します。今回はlaptopを検出してみます。
from detic.modeling.text.text_encoder import build_text_encoder
def get_clip_embeddings(vocabulary, prompt='a '):
text_encoder = build_text_encoder(pretrain=True)
text_encoder.eval()
texts = [prompt + x for x in vocabulary]
emb = text_encoder(texts).detach().permute(1, 0).contiguous().cpu()
return emb
vocabulary = 'custom'
metadata = MetadataCatalog.get("__unused")
#@title 検出対象の入力
#@markdown 検出対象の名称を英語で入力してください。
detect_target = 'laptop' #@param {type:"string"}
metadata.thing_classes = [detect_target]
classifier = get_clip_embeddings(metadata.thing_classes)
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)
for file in uploaded:
im = cv2.imread(file)
# Reset visualization threshold
output_score_threshold = 0.3
for cascade_stages in range(len(predictor.model.roi_heads.box_predictor)):
predictor.model.roi_heads.box_predictor[cascade_stages].test_score_thresh = output_score_threshold
# Run model and show results
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
del metadata.thing_classes
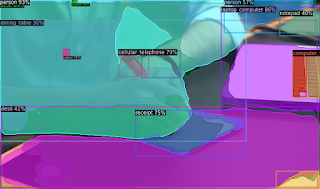
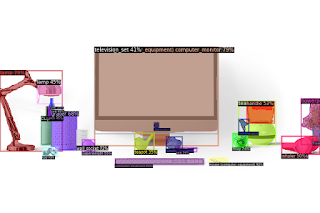
検出結果は以下の通りです。
なかなか正確に検出されていますね。
最後にvocabularyをロードし、検出できる対象を全て検出してみます。
# Setup the model's vocabulary using build-in datasets
BUILDIN_CLASSIFIER = {
'lvis': 'datasets/metadata/lvis_v1_clip_a+cname.npy',
'objects365': 'datasets/metadata/o365_clip_a+cnamefix.npy',
'openimages': 'datasets/metadata/oid_clip_a+cname.npy',
'coco': 'datasets/metadata/coco_clip_a+cname.npy',
}
BUILDIN_METADATA_PATH = {
'lvis': 'lvis_v1_val',
'objects365': 'objects365_v2_val',
'openimages': 'oid_val_expanded',
'coco': 'coco_2017_val',
}
vocabulary = 'lvis' # change to 'lvis', 'objects365', 'openimages', or 'coco'
metadata = MetadataCatalog.get(BUILDIN_METADATA_PATH[vocabulary])
classifier = BUILDIN_CLASSIFIER[vocabulary]
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)
lvisのデータセットからvocabularyをロードします。
for file in uploaded:
im = cv2.imread(file)
# Reset visualization threshold
output_score_threshold = 0.3
for cascade_stages in range(len(predictor.model.roi_heads.box_predictor)):
predictor.model.roi_heads.box_predictor[cascade_stages].test_score_thresh = output_score_threshold
# Run model and show results
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
検出結果は以下の通りです。
非常に細部まで物体が検出できることがわかります。
まとめ
本記事では、Deticを使って任意のキーワードの物体を検出する方法をご紹介しました。
データセットの確保を容易にしつつ、従来機能を拡張し、さらに精度も良いとなるとなかなか驚異的です。
実際作成してみると痛感しますが、物体検出データセットのアノテーション付与はなかなか苦痛な作業です。Deticでその作業から解放されるのであれば多くの人が救われるのではないでしょうか。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
リンク
リンク
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1.
論文 - Detecting Twenty-thousand Classes using Image-level Supervision
2. GitHub - facebookresearch/Detic
















0 件のコメント :
コメントを投稿