本記事では、MMOCRと呼ばれるオープンソースで構成されたAIOCRツールセットを使って文字検出、文字認識、キー情報抽出を行う方法を紹介します。

MMOCR
概要
MMOCRは、文字検出(text detection)・文字認識(text recognition)・キー情報抽出(key
information extraction)の予測・学習・評価を提供するツールセットです。Pytorchとmmdetectionをベースとしており、オープンソースプロジェクトであるOpenMMLabプロジェクトにより開発されています。
文字検出・文字認識をサポートするオープンソースは他にも存在しますが、キー情報抽出もサポートしている点が特徴的です。
また、コマンドラインから実行することはできませんが、固有表現抽出(Named Entity Recognition)のモデルであるBert-Softmaxもサポートしています。
主な機能
-
包括的パイプライン
文字検出・文字認識だけではなく、キー情報抽出などの自然言語処理系の個別タスク(ダウンストリームタスク)もサポート -
複数モデルのサポ―ト
文字検出・文字認識キー情報抽出などにおいて最先端の様々なモデルをサポート
文字認識だけでも2021年発表のモデルを含め7種のモデルをサポート -
モジュラー設計
モジュラー設計により、ユーザーは独自のオプティマイザー、データプリプロセッサー、およびバックボーン、ネック、ヘッドなどのモデルコンポーネント、および損失を定義可能 -
多数のユーティリティ
予測結果を視覚化するビジュアライザや、予測結果の精度を検証する検証ツールをサポート
やや乱暴な言い方ですが、学習データさえ準備すれば、サポートされているモデルの学習、検証、予測が簡単に実現できます。
特に、文字検出用のIoUの算出、文字認識用のACCの算出など、評価までしっかりケアされている点が素晴らしいです。
MMOCRの導入手順
セットアップ①: conda環境構築
それでは早速、開発環境にMMOCRをセットアップしていきます。
動作確認は下記の環境で行っています。
OS: Ubuntu 18.04.3 LTS
GPU: GeForce GTX 1080
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
それでは、MMOCRをインストールしていきます。他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
またMMOCRの前提条件は以下の通りです。特にWindowsは公式には非サポートです。ご注意ください。
- Linux (Windowsは公式には非サポート)
- Python 3.7
- PyTorch >= 1.6
- torchvision 0.7.0
- CUDA 10.1
- NCCL 2
- GCC >= 5.4.0
- MMCV >= 1.3.8
- MMDetection >= 2.14.0
それではセットアップしていきます。
セットアップ②: データセットのダウンロード
続いて、キー情報抽出の実行に必要な辞書ファイルをダウンロードします。
以上でセットアップは完了です。
OCR(文字検出+文字認識)の実行
英語
セットアップが完了したので、早速OCRから試していきます。
なお、今回試すコマンドで使用するオプションはあくまで一例です。文字検出に使用するアルゴリズムの変更等々
実行時のオプションはmmocr/utils/ocr.pyに記載されていますのでご確認ください。
上記の実行結果は以下の通りです。

一部検出漏れが見受けられますが、検出できている文字に対しては、概ね良好に文字認識できています。
日本語
日本語のレシートのOCR結果は以下の通りです。
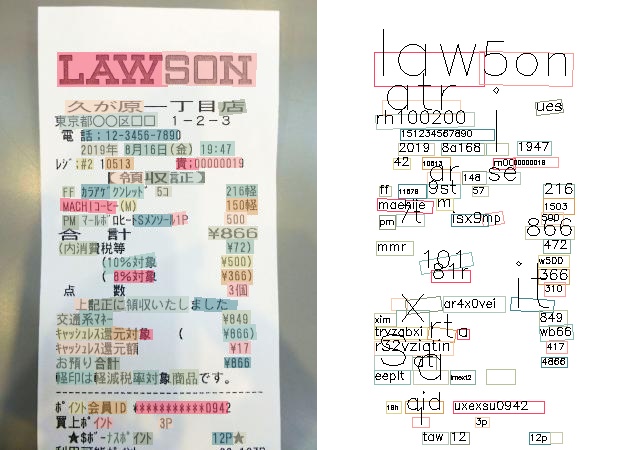
MMOCRから提供されているモデルでは日本語は未対応のようです。
日本語を認識させたい場合は、別途日本語のトレーニングが必要のようです。
文字検出(text detection)の実行
英語

日本語

文字検出においては、言語の影響はあまりありません。正常に検出できています。
キー情報抽出(key information extraction)の実行
文字認識時に日本語の認識ができていないため、キー情報抽出においても日本語の抽出はできないことが明白なため英語のみ確認します。

日付(Date_value)、時刻(Time_value)、小計(Subtotal_value)、税額(Tax_value)、合計(Total_value)などの情報が抽出されていることが確認できます。
まとめ
本記事では、MMOCRを使って文字検出、文字認識、キー情報抽出を行う方法を紹介しました。
機械学習が浸透するにつれ、モデルそのものを実装せずとも様々なタスクの予測が可能になっています。
だからこそ、ブラックボックス化が進んでしまい、予測結果の説明ができないと技術に振り回されかねないので仕組みを理解していくことは重要だと考えます。
本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. 論文 - MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
3. mmocr demo






0 件のコメント :
コメントを投稿