本記事では、pix2pixを使って、手書きフォントをAIに自動生成させる方法を紹介します。

pix2pixとは
画像から画像へと変換を行うGANを利用した画像生成技術です。
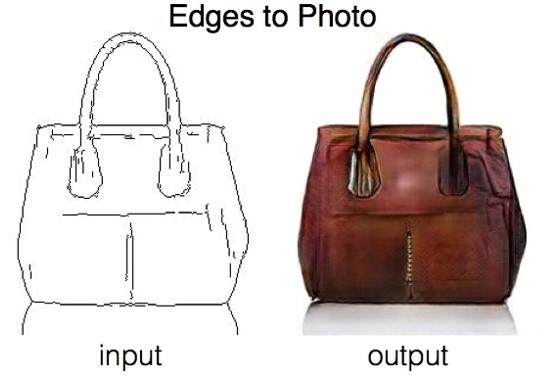
|
| 出典: https://github.com/phillipi/pix2pix |
上図は、pix2pixで実現できるタスクの一つですが、線画を入力すると、その線画の特徴を解釈して写真のような画像を出力します。
pix2pixは、2つのペアとなる画像間の特徴を学習し、ペアの一方を入力した場合に、もう一方との特徴を補完した画像を出力します。
CLOVA
OCRはなぜこんなに認識精度が高いのか?AIで「手書きフォント」を作ったLINE
CLOVAの開発秘話の記事で紹介されていますが、LINE社のCLOVA
OCRにもこのpix2pixの技術が応用されています。
手書き文字を生成するためには、活字文字画像と手書き文字画像のペア画像を用意し、モデルをトレーニングします。
そして、活字文字画像を入力した際に、手書き文字画像を出力させます。
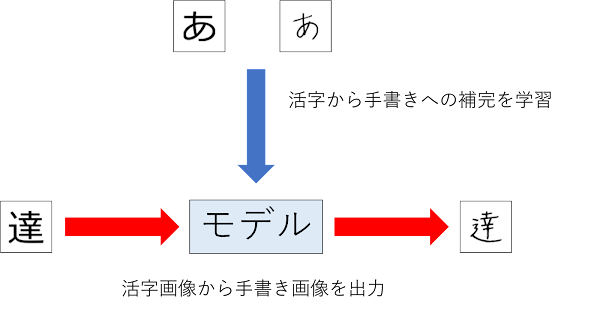
上図は、かなり簡略化していますが、手書き文字画像を生成するまでの概念図です。
特徴としては、モデルは活字から手書きへの補完方法を学習します。
どのような文字であるかはモデルは理解する必要がありません。
つまり、数百枚の手書き文字画像を学習させてしまえば、様々な活字文字画像を入力することによって、様々な手書き文字画像を生成できます。
pix2pixの導入手順
セットアップ①: conda環境構築
それでは早速、開発環境にpix2pixをセットアップしていきます。
動作確認は下記の環境で行っています。
OS: Ubuntu 18.04.3 LTS
GPU: GeForce GTX 1080
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
それでは、pix2pixをインストールしていきます。他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
以上でpix2pixの環境セットアップは完了です。
セットアップ②: 学習データの準備
環境セットアップの次に、学習データの準備を行います。
具体的には、活字文字画像と手書き文字画像のペア画像を作成していきます。
活字文字はメイリオを手書き文字は、今回は手書き風フォントモギハ・ペン字フォントを使用させていただきます。
この二つを実行するとそれぞれ、メイリオとモギハ・ペン字の一文字ごとの文字画像が生成されます。


続いて生成したデータを学習データと、テストデータに振り分けます。
最後に、このままでは手書き風フォントを再現するモデルとなってしまうため入力画像にぼかし処理を付与します。

セットアップ③: モデルのトレーニング
最後にモデルをトレーニングします。
GPUの有無などの環境にもよりますが、約2時間ほど学習時間を要します。
手書き文字の出力
モデルに活字文字画像を入力して手書き文字画像を出力させた結果が以下の通りです。

学習エポック数や、入力画像とする手書き文字、ぼかし処理の有無などによっても出力結果は異なってきます。
つまり、様々な形状の手書き文字が生成できます。
まとめ
本記事では、pix2pixを使って、手書き文字画像を生成する方法を紹介しました。
このような方法で手書き文字画像を収集できれば、手書き文字認識の学習データの確保において大きなコストダウンを図りながら
精度向上を目指せそうですね。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. CLOVA OCRはなぜこんなに認識精度が高いのか?AIで「手書きフォント」を作ったLINE CLOVAの開発秘話
2. 論文 - Image-to-Image Translation with Conditional Adversarial Networks






0 件のコメント :
コメントを投稿