本記事では、2022年1月にSalesforceより発表されたBLIPと呼ばれる機械学習手法を使って画像のキャプションを生成する方法を紹介します。

BLIP
概要
BLIPは、2022年1月にSalesforceより論文発表された、視覚言語理解と視覚言語生成の両方に柔軟に対応する新しいVision-Language
Pre-training(VLP)フレームワークです。
入力された画像に対するキャプションの生成(image
captioning)では、CIDErで+2.8%、画像に対する質問に答えるVQAでは、VQAスコアで+1.6%など幅広い視覚言語タスクで最先端の結果を示している手法です。またvideo
QAなどビデオ言語タスクに転移することでゼロショットパフォーマンスを発揮します。
導入
従来のVLPには、下記2点の課題が存在します。
-
視覚言語理解と視覚言語生成の両方に未対応
既存のVLPはエンコーダーベースモデル、エンコーダー・デコーダーモデルを採用しています。エンコーダーベースモデルは、キャプション生成などの視覚言語生成への転移が困難であり、エンコーダー・デコーダーモデルは、画像とテキストの探索などの視覚言語理解へ上手く適用されていません。 -
ノイズの多いWebテキスト
CLIPなどはWebから収集された画像とテキストのペアを事前にトレーニングしています。しかし、BLIPの論文では、ノイズの多いWebテキストが視覚言語学習に最適ではないことを示しています。
BLIPでは、上記2点の課題を以下の方法で解決しています。
-
Multimodal mixture of Encoder-Decoder(MED)
MEDは、画像に基づいたエンコーダー・デコーダーとして動作し、視覚言語理解、視覚言語生成に対して柔軟な転移学習を可能にするアーキテクチャです。 -
Captioning and Filtering (CapFilt)
ノイズの多い画像とテキストのペアから学習するための新しいデータセットブーストラッピング法です。
事前トレーニングされたMEDを2つのモジュールに微調整します。1つはWeb画像に基づいて合成キャプションを生成するキャプション作成者、
もう1つは元のWebテキストと合成テキストの両方からノイズの多いキャプションを削除するフィルターです。
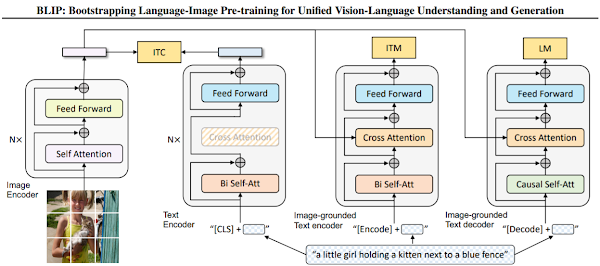
|
| 出典: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation |
上図はBLIPの概念図です。BLIPは下記3つの機能のいずれかで動作する統一されたモデルです。
- ユニモーダルエンコーダーは、視覚と言語表現を調整するために、image-text contrastive (ITC) lossでトレーニングされます。
- 画像に基づくテキストエンコーダー(Image-grounded text encoder)は、cross attentionレイヤーを使用して、視覚と言語の相互作用をモデル化し、image-text matching (ITM) lossでトレーニングされます。
- 画像に基づくテキストデコーダー(Image-grounded text decoder)は、 language modeling (LM) lossでトレーニングされ、画像に与えられたキャプションを生成します。
デモ(Colaboratory)
イメージが付きづらいと思いますので、実際に動かしながらBLIPができることを見ていきます。
ソースコードは本記事にも記載していますが、下記のGitHubでも取得可能です。
GitHub - Colaboratory demo
また、下記から直接Google Colaboratoryで開くこともできます。
![]()
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
環境セットアップ
それではセットアップしていきます。 Colaboratoryを開いたら下記を設定しGPUを使用するようにしてください。
次にライブラリのインストール及び、BLIPのソースコードをGitHubから取得します。
テスト画像のセットアップ
次に、BLIPのデモに使用するテスト画像をセットアップします。
本記事では、ぱくたそ様の下記の画像を使用させていただきます。
レモンを持ったスムージー女子の写真素材

Image Captioningのセットアップ
上記テスト画像を入力として、BLIPにキャプションを予測させてみます。
始めに事前学習済みモデルをロードします。
Image Captioning
それでは、キャプションを生成させてみます。
キャプションの出力結果は以下の通りです。
女性がテーブルの前に座っていること、フルーツや野菜が置いてあることなどが表現されていますね。
Visual question answering(VQA)のセットアップ
続いて、画像に対するQandAに答えるVQAのために学習済みモデルをロードします。
Visual question answering(VQA)
それでは、VQAを実施します。
上記では'where is the woman sitting?'と質問しています。
回答は以下の通りです。
このほかにも様々な質問を試してみました。
非常に妥当性の高い答えが返ってきています。
画像中に犬がいないことを理解した上で「no
dogs」と返答したり、右手と左手を理解した上で「lemon」と返答しています。
この写真を見てどう思う?のような抽象的な質問に対しては、静物画(花、果実など動かないモノを主体的に描いた絵画)であるとそっけない返答をされていますが、概ね間違った回答ではありません。
そのままでも、実務に適用できてしまうのではと思わされるほどの性能です。
まとめ
本記事では、BLIPを使って画像のキャプション生成、VQAを行う方法を紹介しました。
CLIP同様テキストから画像生成など様々な用途に応用されていくことが見込まれます。今後の動向にも注視したい技術です。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。






0 件のコメント :
コメントを投稿