本記事では、VQGAN+CLIPを使用して、任意のテキストや、画像からアニメーションを作成する方法をご紹介します。

VQGAN+CLIP
概要
VQGAN+CLIPとは、自然言語表現のテキストを入力に、入力テキストと意味的関連性の高い画像を出力するText
to Imageタスクを実現する技術です。
簡単な理解としては、GANを用いて画像を生成し、CLIPを用いて生成した画像と入力テキストの関連性を採点します。その後、採点結果を反映して再度画像生成という処理を繰り返していくことで、入力テキストと意味的関連性の高い画像を出力します。
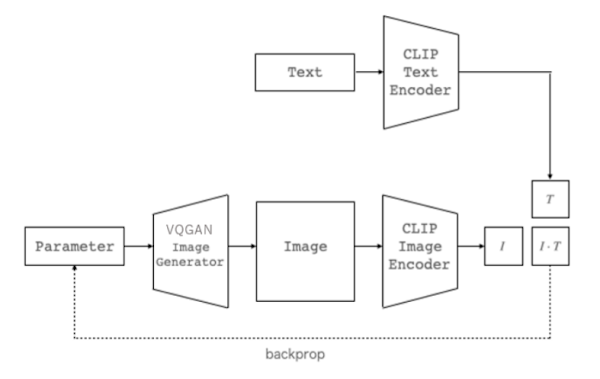
|
| 出典: CLIP を用いた画像ランキングによるパラメータ最適化に基づいた絵本の挿絵生成 |
上図のように、ジェネレータ(GAN)が画像生成し、エンコーダー(CLIP)が画像とテキストを採点(CLIPスコア算出)することによりText
to Imageタスクが実現されています。
本記事では、GANに入力するパラメータを徐々に変化させ、パタパタ漫画のように徐々に変化する画像(フレーム画像)を大量に生成します。
その後フレーム画像を一つの動画にまとめることでアニメーションを作成していきます。
また、以下の記事では、Text to
Image手法を用いて任意のテキストから画像を生成する方法をご紹介しています。
まずは画像を生成してみたいという方はこちらをご参照ください。
[FuseDream] AIを使ってテキストから絵を描く [日本語対応]
FuseDreamと呼ばれる機械学習手法を用いてAIにテキストを入力し画像を生成させる方法を紹介しています。
デモ(Colaboratory)
それでは、実際に動かしながらVQGAN+CLIPによるアニメーションを行っていきます。
ソースコードは本記事にも記載していますが、下記のGitHubでも取得可能です。
GitHub - Colaboratory demo
また、下記から直接Google Colaboratoryで開くこともできます。
![]()
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
環境セットアップ
それではまず環境からセットアップしていきます。 Colaboratoryを開いたら下記を設定しGPUを使用するようにしてください。
始めに、Google ColaboratoryからGoogle
Driveにアクセスできるようにマウントします。
マウント後、Google
Drive上に作業ディレクトリを作成します。この作業ディレクトリには、生成画像や動画が格納されます。
from google.colab import drive
drive.mount('/content/drive')
!mkdir '/content/drive/MyDrive/vqgan'
!mkdir '/content/drive/MyDrive/vqgan/images'
working_dir = '/content/drive/MyDrive/vqgan'
次にライブラリをインストールしていきます。
%cd /content/
print("Downloading CLIP...")
!git clone https://github.com/openai/CLIP &> /dev/null
print("Downloading Python AI libraries...")
!git clone https://github.com/CompVis/taming-transformers &> /dev/null
!pip install ftfy regex tqdm omegaconf pytorch-lightning &> /dev/null
!pip install kornia &> /dev/null
!pip install einops &> /dev/null
print("Installing libraries for handling metadata...")
!pip install stegano &> /dev/null
!apt install exempi &> /dev/null
!pip install python-xmp-toolkit &> /dev/null
!pip install imgtag &> /dev/null
!pip install pillow==7.1.2 &> /dev/null
print("Installing Python video creation libraries...")
!pip install imageio-ffmpeg &> /dev/null
path = f'{working_dir}/steps'
!mkdir --parents {path}
print("Installation finished.")
ライブラリをインポートします。
import argparse
import math
from pathlib import Path
import sys
import os
import cv2
import pandas as pd
import numpy as np
import subprocess
import ast
sys.path.append('/content/taming-transformers')
# Some models include transformers, others need explicit pip install
try:
import transformers
except Exception:
!pip install transformers
import transformers
from IPython import display
from base64 import b64encode
from omegaconf import OmegaConf
from PIL import Image
from taming.models import cond_transformer, vqgan
import torch
from torch import nn, optim
from torch.nn import functional as F
from torchvision import transforms
from torchvision.transforms import functional as TF
from tqdm.notebook import tqdm
from CLIP import clip
import kornia.augmentation as K
import numpy as np
import imageio
from PIL import ImageFile, Image
from imgtag import ImgTag # metadata
from libxmp import * # metadata
import libxmp # metadata
from stegano import lsb
import json
ImageFile.LOAD_TRUNCATED_IMAGES = True
環境セットアップの最後に各処理で用いる関数を定義しておきます。
なお、実装を意識せずともアニメーション作成は可能です。実装を確認したい場合は以下を展開してご確認ください。
def sinc(x):
return torch.where(x != 0, torch.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
def lanczos(x, a):
cond = torch.logical_and(-a < x, x < a)
out = torch.where(cond, sinc(x) * sinc(x/a), x.new_zeros([]))
return out / out.sum()
def ramp(ratio, width):
n = math.ceil(width / ratio + 1)
out = torch.empty([n])
cur = 0
for i in range(out.shape[0]):
out[i] = cur
cur += ratio
return torch.cat([-out[1:].flip([0]), out])[1:-1]
def resample(input, size, align_corners=True):
n, c, h, w = input.shape
dh, dw = size
input = input.view([n * c, 1, h, w])
if dh < h:
kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
pad_h = (kernel_h.shape[0] - 1) // 2
input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
input = F.conv2d(input, kernel_h[None, None, :, None])
if dw < w:
kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
pad_w = (kernel_w.shape[0] - 1) // 2
input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
input = F.conv2d(input, kernel_w[None, None, None, :])
input = input.view([n, c, h, w])
return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
class ReplaceGrad(torch.autograd.Function):
@staticmethod
def forward(ctx, x_forward, x_backward):
ctx.shape = x_backward.shape
return x_forward
@staticmethod
def backward(ctx, grad_in):
return None, grad_in.sum_to_size(ctx.shape)
replace_grad = ReplaceGrad.apply
class ClampWithGrad(torch.autograd.Function):
@staticmethod
def forward(ctx, input, min, max):
ctx.min = min
ctx.max = max
ctx.save_for_backward(input)
return input.clamp(min, max)
@staticmethod
def backward(ctx, grad_in):
input, = ctx.saved_tensors
return grad_in * (grad_in * (input - input.clamp(ctx.min, ctx.max)) >= 0), None, None
clamp_with_grad = ClampWithGrad.apply
def vector_quantize(x, codebook):
d = x.pow(2).sum(dim=-1, keepdim=True) + codebook.pow(2).sum(dim=1) - 2 * x @ codebook.T
indices = d.argmin(-1)
x_q = F.one_hot(indices, codebook.shape[0]).to(d.dtype) @ codebook
return replace_grad(x_q, x)
class Prompt(nn.Module):
def __init__(self, embed, weight=1., stop=float('-inf')):
super().__init__()
self.register_buffer('embed', embed)
self.register_buffer('weight', torch.as_tensor(weight))
self.register_buffer('stop', torch.as_tensor(stop))
def forward(self, input):
input_normed = F.normalize(input.unsqueeze(1), dim=2)
embed_normed = F.normalize(self.embed.unsqueeze(0), dim=2)
dists = input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2)
dists = dists * self.weight.sign()
return self.weight.abs() * replace_grad(dists, torch.maximum(dists, self.stop)).mean()
def parse_prompt(prompt):
vals = prompt.rsplit(':', 2)
vals = vals + ['', '1', '-inf'][len(vals):]
return vals[0], float(vals[1]), float(vals[2])
class MakeCutouts(nn.Module):
def __init__(self, cut_size, cutn, cut_pow=1.):
super().__init__()
self.cut_size = cut_size
self.cutn = cutn
self.cut_pow = cut_pow
self.augs = nn.Sequential(
K.RandomHorizontalFlip(p=0.5),
# K.RandomSolarize(0.01, 0.01, p=0.7),
K.RandomSharpness(0.3,p=0.4),
K.RandomAffine(degrees=30, translate=0.1, p=0.8, padding_mode='border'),
K.RandomPerspective(0.2,p=0.4),
K.ColorJitter(hue=0.01, saturation=0.01, p=0.7))
self.noise_fac = 0.1
def forward(self, input):
sideY, sideX = input.shape[2:4]
max_size = min(sideX, sideY)
min_size = min(sideX, sideY, self.cut_size)
cutouts = []
for _ in range(self.cutn):
size = int(torch.rand([])**self.cut_pow * (max_size - min_size) + min_size)
offsetx = torch.randint(0, sideX - size + 1, ())
offsety = torch.randint(0, sideY - size + 1, ())
cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
batch = self.augs(torch.cat(cutouts, dim=0))
if self.noise_fac:
facs = batch.new_empty([self.cutn, 1, 1, 1]).uniform_(0, self.noise_fac)
batch = batch + facs * torch.randn_like(batch)
return batch
def load_vqgan_model(config_path, checkpoint_path):
config = OmegaConf.load(config_path)
if config.model.target == 'taming.models.vqgan.VQModel':
model = vqgan.VQModel(**config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
elif config.model.target == 'taming.models.cond_transformer.Net2NetTransformer':
parent_model = cond_transformer.Net2NetTransformer(**config.model.params)
parent_model.eval().requires_grad_(False)
parent_model.init_from_ckpt(checkpoint_path)
model = parent_model.first_stage_model
else:
raise ValueError(f'unknown model type: {config.model.target}')
del model.loss
return model
def resize_image(image, out_size):
ratio = image.size[0] / image.size[1]
area = min(image.size[0] * image.size[1], out_size[0] * out_size[1])
size = round((area * ratio)**0.5), round((area / ratio)**0.5)
return image.resize(size, Image.LANCZOS)
Default画像の取得
VQGAN+CLIPでは、画像生成時に、入力テキストと同時に初期画像やターゲット画像を指定することができます。
ここでは初期画像などに使用するデフォルト画像を事前にダウンロードしておきます。
%cd /content/drive/MyDrive/vqgan/images
!wget https://www.pakutaso.com/shared/img/thumb/nantoshi21PAR519902088_TP_V4.jpg
!wget https://www.pakutaso.com/shared/img/thumb/yuka16011215IMG_5574_TP_V4.jpg
src_img = Image.open('/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg')
dst_img = Image.open('/content/drive/MyDrive/vqgan/images/yuka16011215IMG_5574_TP_V4.jpg')
src_img = src_img.resize((src_img.width // 2, src_img.height // 2))
dst_img = dst_img.resize((dst_img.width // 2, dst_img.height // 2))
src_img.save('/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg')
dst_img.save('/content/drive/MyDrive/vqgan/images/yuka16011215IMG_5574_TP_V4.jpg')
%cd /content/
以下の画像をダウンロードしてGoogle Drive内に保存しています。
なお、下記以外の画像を使用することも可能ですが、画像サイズにはご注意ください。
画像サイズが大きい場合メモリを超過する場合があります。
本記事では、そのままの画像サイズだとメモリを超過するため半分のサイズにリサイズしています。

パラメータ設定
フレーム画像生成時にパラメータを設定します。
特に重要なパラメーターは以下の通りです。
-
text_prompts
GANに入力するクエリテキスト。
'Moon': {10: 0, 60: 1}の場合、Moonというクエリテキストを10フレーム目では0(最小)で、60フレーム目には1(最大)になるように入力。 -
initial_image
初期画像。必要ない場合空欄でも可。
本記事では先ほどセットアップした画像を設定。"/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg" -
target_images
ターゲット画像。必要ない場合空欄でも可。
本記事では先ほどセットアップした画像を設定。"/content/drive/MyDrive/vqgan/images/yuka16011215IMG_5574_TP_V4.jpg': {10: 0, 60: 1}"
上記設定では、クエリテキスト同様に、10フレーム目には最小、60フレーム目で最大になるように入力される。 -
zoom
各フレームをズームインするための係数、1はズームなし、1未満はズームアウト、1を超える場合はズームイン(正の値のみ)(E.g. 10: 1, 30: 1.2, 50: 0.9)
key_frames = True #@param {type:"boolean"}
text_prompts = "'Moon': {10: 0, 60: 1}, 'Sun': {10: 1, 60: 0}" #@param {type:"string"}
width = 400 #@param {type:"number"}
height = 400 #@param {type:"number"}
model = "vqgan_imagenet_f16_16384" #@param ["vqgan_imagenet_f16_16384", "vqgan_imagenet_f16_1024", "wikiart_16384", "coco", "faceshq", "sflckr"]
interval = 1#@param {type:"number"}
initial_image = "/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg"#@param {type:"string"}
target_images = "'/content/drive/MyDrive/vqgan/images/yuka16011215IMG_5574_TP_V4.jpg': {10: 0, 60: 1}"#@param {type:"string"}
seed = 1#@param {type:"number"}
max_frames = 60#@param {type:"number"}
angle = "10: 0, 30: 1, 60: -1"#@param {type:"string"}
# @markdown Careful: do not use negative or 0 zoom. If you want to zoom out, use a number between 0 and 1.
zoom = "10: 1, 30: 1.2, 60: 0.9"#@param {type:"string"}
translation_x = "0: 0"#@param {type:"string"}
translation_y = "0: 0"#@param {type:"string"}
iterations_per_frame = "0: 10"#@param {type:"string"}
save_all_iterations = False#@param {type:"boolean"}
設定したパラメータを基に各フレームに入力するパラメータを生成します。
# option -C - skips download if already exists
!curl -C - -L -o {model}.yaml -C - 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1' #ImageNet 1024
!curl -C - -L -o {model}.ckpt -C - 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fckpts%2Flast.ckpt&dl=1' #ImageNet 1024
if initial_image != "":
print(
"WARNING: You have specified an initial image. Note that the image resolution "
"will be inherited from this image, not whatever width and height you specified. "
"If the initial image resolution is too high, this can result in out of memory errors."
)
elif width * height > 160000:
print(
"WARNING: The width and height you have specified may be too high, in which case "
"you will encounter out of memory errors either at the image generation stage or the "
"video synthesis stage. If so, try reducing the resolution"
)
model_names={
"vqgan_imagenet_f16_16384": 'ImageNet 16384',
"vqgan_imagenet_f16_1024":"ImageNet 1024",
"wikiart_1024":"WikiArt 1024",
"wikiart_16384":"WikiArt 16384",
"coco":"COCO-Stuff",
"faceshq":"FacesHQ",
"sflckr":"S-FLCKR"
}
model_name = model_names[model]
if seed == -1:
seed = None
def parse_key_frames(string, prompt_parser=None):
"""Given a string representing frame numbers paired with parameter values at that frame,
return a dictionary with the frame numbers as keys and the parameter values as the values.
Parameters
----------
string: string
Frame numbers paired with parameter values at that frame number, in the format
'framenumber1: (parametervalues1), framenumber2: (parametervalues2), ...'
prompt_parser: function or None, optional
If provided, prompt_parser will be applied to each string of parameter values.
Returns
-------
dict
Frame numbers as keys, parameter values at that frame number as values
Raises
------
RuntimeError
If the input string does not match the expected format.
Examples
--------
>>> parse_key_frames("10:(Apple: 1| Orange: 0), 20: (Apple: 0| Orange: 1| Peach: 1)")
{10: 'Apple: 1| Orange: 0', 20: 'Apple: 0| Orange: 1| Peach: 1'}
>>> parse_key_frames("10:(Apple: 1| Orange: 0), 20: (Apple: 0| Orange: 1| Peach: 1)", prompt_parser=lambda x: x.lower()))
{10: 'apple: 1| orange: 0', 20: 'apple: 0| orange: 1| peach: 1'}
"""
try:
# This is the preferred way, the regex way will eventually be deprecated.
frames = ast.literal_eval('{' + string + '}')
if isinstance(frames, set):
# If user forgot keyframes, just set value of frame 0
(frame,) = list(frames)
frames = {0: frame}
return frames
except Exception:
import re
pattern = r'((?P[0-9]+):[\s]*[\(](?P[\S\s]*?)[\)])'
frames = dict()
for match_object in re.finditer(pattern, string):
frame = int(match_object.groupdict()['frame'])
param = match_object.groupdict()['param']
if prompt_parser:
frames[frame] = prompt_parser(param)
else:
frames[frame] = param
if frames == {} and len(string) != 0:
raise RuntimeError(f'Key Frame string not correctly formatted: {string}')
return frames
# Defaults, if left empty
if angle == "":
angle = "0"
if zoom == "":
zoom = "1"
if translation_x == "":
translation_x = "0"
if translation_y == "":
translation_y = "0"
if iterations_per_frame == "":
iterations_per_frame = "10"
if key_frames:
parameter_dicts = dict()
parameter_dicts['zoom'] = parse_key_frames(zoom, prompt_parser=float)
parameter_dicts['angle'] = parse_key_frames(angle, prompt_parser=float)
parameter_dicts['translation_x'] = parse_key_frames(translation_x, prompt_parser=float)
parameter_dicts['translation_y'] = parse_key_frames(translation_y, prompt_parser=float)
parameter_dicts['iterations_per_frame'] = parse_key_frames(iterations_per_frame, prompt_parser=int)
text_prompts_dict = parse_key_frames(text_prompts)
if all([isinstance(value, dict) for value in list(text_prompts_dict.values())]):
for key, value in list(text_prompts_dict.items()):
parameter_dicts[f'text_prompt: {key}'] = value
else:
# Old format
text_prompts_dict = parse_key_frames(text_prompts, prompt_parser=lambda x: x.split('|'))
for frame, prompt_list in text_prompts_dict.items():
for prompt in prompt_list:
prompt_key, prompt_value = prompt.split(":")
prompt_key = f'text_prompt: {prompt_key.strip()}'
prompt_value = prompt_value.strip()
if prompt_key not in parameter_dicts:
parameter_dicts[prompt_key] = dict()
parameter_dicts[prompt_key][frame] = prompt_value
image_prompts_dict = parse_key_frames(target_images)
if all([isinstance(value, dict) for value in list(image_prompts_dict.values())]):
for key, value in list(image_prompts_dict.items()):
parameter_dicts[f'image_prompt: {key}'] = value
else:
# Old format
image_prompts_dict = parse_key_frames(target_images, prompt_parser=lambda x: x.split('|'))
for frame, prompt_list in image_prompts_dict.items():
for prompt in prompt_list:
prompt_key, prompt_value = prompt.split(":")
prompt_key = f'image_prompt: {prompt_key.strip()}'
prompt_value = prompt_value.strip()
if prompt_key not in parameter_dicts:
parameter_dicts[prompt_key] = dict()
parameter_dicts[prompt_key][frame] = prompt_value
def add_inbetweens():
global text_prompts
global target_images
global zoom
global angle
global translation_x
global translation_y
global iterations_per_frame
global text_prompts_series
global target_images_series
global zoom_series
global angle_series
global translation_x_series
global translation_y_series
global iterations_per_frame_series
global model
global args
def get_inbetweens(key_frames_dict, integer=False):
"""Given a dict with frame numbers as keys and a parameter value as values,
return a pandas Series containing the value of the parameter at every frame from 0 to max_frames.
Any values not provided in the input dict are calculated by linear interpolation between
the values of the previous and next provided frames. If there is no previous provided frame, then
the value is equal to the value of the next provided frame, or if there is no next provided frame,
then the value is equal to the value of the previous provided frame. If no frames are provided,
all frame values are NaN.
Parameters
----------
key_frames_dict: dict
A dict with integer frame numbers as keys and numerical values of a particular parameter as values.
integer: Bool, optional
If True, the values of the output series are converted to integers.
Otherwise, the values are floats.
Returns
-------
pd.Series
A Series with length max_frames representing the parameter values for each frame.
Examples
--------
>>> max_frames = 5
>>> get_inbetweens({1: 5, 3: 6})
0 5.0
1 5.0
2 5.5
3 6.0
4 6.0
dtype: float64
>>> get_inbetweens({1: 5, 3: 6}, integer=True)
0 5
1 5
2 5
3 6
4 6
dtype: int64
"""
key_frame_series = pd.Series([np.nan for a in range(max_frames)])
for i, value in key_frames_dict.items():
key_frame_series[i] = value
key_frame_series = key_frame_series.astype(float)
key_frame_series = key_frame_series.interpolate(limit_direction='both')
if integer:
return key_frame_series.astype(int)
return key_frame_series
if key_frames:
text_prompts_series_dict = dict()
for parameter in parameter_dicts.keys():
if len(parameter_dicts[parameter]) > 0:
if parameter.startswith('text_prompt:'):
try:
text_prompts_series_dict[parameter] = get_inbetweens(parameter_dicts[parameter])
except RuntimeError as e:
raise RuntimeError(
"WARNING: You have selected to use key frames, but you have not "
"formatted `text_prompts` correctly for key frames.\n"
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
text_prompts_series = pd.Series([np.nan for a in range(max_frames)])
for i in range(max_frames):
combined_prompt = []
for parameter, value in text_prompts_series_dict.items():
parameter = parameter[len('text_prompt:'):].strip()
combined_prompt.append(f'{parameter}: {value[i]}')
text_prompts_series[i] = ' | '.join(combined_prompt)
image_prompts_series_dict = dict()
for parameter in parameter_dicts.keys():
if len(parameter_dicts[parameter]) > 0:
if parameter.startswith('image_prompt:'):
try:
image_prompts_series_dict[parameter] = get_inbetweens(parameter_dicts[parameter])
except RuntimeError as e:
raise RuntimeError(
"WARNING: You have selected to use key frames, but you have not "
"formatted `image_prompts` correctly for key frames.\n"
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
target_images_series = pd.Series([np.nan for a in range(max_frames)])
for i in range(max_frames):
combined_prompt = []
for parameter, value in image_prompts_series_dict.items():
parameter = parameter[len('image_prompt:'):].strip()
combined_prompt.append(f'{parameter}: {value[i]}')
target_images_series[i] = ' | '.join(combined_prompt)
try:
angle_series = get_inbetweens(parameter_dicts['angle'])
except RuntimeError as e:
print(
"WARNING: You have selected to use key frames, but you have not "
"formatted `angle` correctly for key frames.\n"
"Attempting to interpret `angle` as "
f'"0: ({angle})"\n'
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
angle = f"0: ({angle})"
angle_series = get_inbetweens(parse_key_frames(angle))
try:
zoom_series = get_inbetweens(parameter_dicts['zoom'])
except RuntimeError as e:
print(
"WARNING: You have selected to use key frames, but you have not "
"formatted `zoom` correctly for key frames.\n"
"Attempting to interpret `zoom` as "
f'"0: ({zoom})"\n'
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
zoom = f"0: ({zoom})"
zoom_series = get_inbetweens(parse_key_frames(zoom))
for i, zoom in enumerate(zoom_series):
if zoom <= 0:
print(
f"WARNING: You have selected a zoom of {zoom} at frame {i}. "
"This is meaningless. "
"If you want to zoom out, use a value between 0 and 1. "
"If you want no zoom, use a value of 1."
)
try:
translation_x_series = get_inbetweens(parameter_dicts['translation_x'])
except RuntimeError as e:
print(
"WARNING: You have selected to use key frames, but you have not "
"formatted `translation_x` correctly for key frames.\n"
"Attempting to interpret `translation_x` as "
f'"0: ({translation_x})"\n'
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
translation_x = f"0: ({translation_x})"
translation_x_series = get_inbetweens(parse_key_frames(translation_x))
try:
translation_y_series = get_inbetweens(parameter_dicts['translation_y'])
except RuntimeError as e:
print(
"WARNING: You have selected to use key frames, but you have not "
"formatted `translation_y` correctly for key frames.\n"
"Attempting to interpret `translation_y` as "
f'"0: ({translation_y})"\n'
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
translation_y = f"0: ({translation_y})"
translation_y_series = get_inbetweens(parse_key_frames(translation_y))
try:
iterations_per_frame_series = get_inbetweens(
parameter_dicts['iterations_per_frame'], integer=True
)
except RuntimeError as e:
print(
"WARNING: You have selected to use key frames, but you have not "
"formatted `iterations_per_frame` correctly for key frames.\n"
"Attempting to interpret `iterations_per_frame` as "
f'"0: ({iterations_per_frame})"\n'
"Please read the instructions to find out how to use key frames "
"correctly.\n"
)
iterations_per_frame = f"0: ({iterations_per_frame})"
iterations_per_frame_series = get_inbetweens(
parse_key_frames(iterations_per_frame), integer=True
)
else:
text_prompts = [phrase.strip() for phrase in text_prompts.split("|")]
if text_prompts == ['']:
text_prompts = []
if target_images == "None" or not target_images:
target_images = []
else:
target_images = target_images.split("|")
target_images = [image.strip() for image in target_images]
angle = float(angle)
zoom = float(zoom)
translation_x = float(translation_x)
translation_y = float(translation_y)
iterations_per_frame = int(iterations_per_frame)
if zoom <= 0:
print(
f"WARNING: You have selected a zoom of {zoom}. "
"This is meaningless. "
"If you want to zoom out, use a value between 0 and 1. "
"If you want no zoom, use a value of 1."
)
args = argparse.Namespace(
prompts=text_prompts,
image_prompts=target_images,
noise_prompt_seeds=[],
noise_prompt_weights=[],
size=[width, height],
init_weight=0.,
clip_model='ViT-B/32',
vqgan_config=f'{model}.yaml',
vqgan_checkpoint=f'{model}.ckpt',
step_size=0.1,
cutn=64,
cut_pow=1.,
display_freq=interval,
seed=seed,
)
add_inbetweens()
フレーム画像の生成
設定したパラメータに基づいてフレーム画像を生成していきます。
パラメータ設定が上手くいっていれば順次フレーム画像の生成が行われます。
path = f'{working_dir}/steps'
!rm -r {path}
!mkdir --parents {path}
#@title Actually do the run...
# Delete memory from previous runs
!nvidia-smi -caa
for var in ['device', 'model', 'perceptor', 'z']:
try:
del globals()[var]
except:
pass
try:
import gc
gc.collect()
except:
pass
try:
torch.cuda.empty_cache()
except:
pass
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
if not key_frames:
if text_prompts:
print('Using text prompts:', text_prompts)
if target_images:
print('Using image prompts:', target_images)
if args.seed is None:
seed = torch.seed()
else:
seed = args.seed
torch.manual_seed(seed)
print('Using seed:', seed)
model = load_vqgan_model(args.vqgan_config, args.vqgan_checkpoint).to(device)
perceptor = clip.load(args.clip_model, jit=False)[0].eval().requires_grad_(False).to(device)
cut_size = perceptor.visual.input_resolution
e_dim = model.quantize.e_dim
f = 2**(model.decoder.num_resolutions - 1)
make_cutouts = MakeCutouts(cut_size, args.cutn, cut_pow=args.cut_pow)
n_toks = model.quantize.n_e
toksX, toksY = args.size[0] // f, args.size[1] // f
sideX, sideY = toksX * f, toksY * f
z_min = model.quantize.embedding.weight.min(dim=0).values[None, :, None, None]
z_max = model.quantize.embedding.weight.max(dim=0).values[None, :, None, None]
stop_on_next_loop = False # Make sure GPU memory doesn't get corrupted from cancelling the run mid-way through, allow a full frame to complete
def read_image_workaround(path):
"""OpenCV reads images as BGR, Pillow saves them as RGB. Work around
this incompatibility to avoid colour inversions."""
im_tmp = cv2.imread(path)
return cv2.cvtColor(im_tmp, cv2.COLOR_BGR2RGB)
for i in range(max_frames):
if stop_on_next_loop:
break
if key_frames:
text_prompts = text_prompts_series[i]
text_prompts = [phrase.strip() for phrase in text_prompts.split("|")]
if text_prompts == ['']:
text_prompts = []
args.prompts = text_prompts
target_images = target_images_series[i]
if target_images == "None" or not target_images:
target_images = []
else:
target_images = target_images.split("|")
target_images = [image.strip() for image in target_images]
args.image_prompts = target_images
angle = angle_series[i]
zoom = zoom_series[i]
translation_x = translation_x_series[i]
translation_y = translation_y_series[i]
iterations_per_frame = iterations_per_frame_series[i]
print(
f'text_prompts: {text_prompts}',
f'image_prompts: {target_images}',
f'angle: {angle}',
f'zoom: {zoom}',
f'translation_x: {translation_x}',
f'translation_y: {translation_y}',
f'iterations_per_frame: {iterations_per_frame}'
)
try:
if i == 0 and initial_image != "":
img_0 = read_image_workaround(initial_image)
z, *_ = model.encode(TF.to_tensor(img_0).to(device).unsqueeze(0) * 2 - 1)
elif i == 0 and not os.path.isfile(f'{working_dir}/steps/{i:04d}.png'):
one_hot = F.one_hot(
torch.randint(n_toks, [toksY * toksX], device=device), n_toks
).float()
z = one_hot @ model.quantize.embedding.weight
z = z.view([-1, toksY, toksX, e_dim]).permute(0, 3, 1, 2)
else:
if save_all_iterations:
img_0 = read_image_workaround(
f'{working_dir}/steps/{i:04d}_{iterations_per_frame}.png')
else:
img_0 = read_image_workaround(f'{working_dir}/steps/{i:04d}.png')
center = (1*img_0.shape[1]//2, 1*img_0.shape[0]//2)
trans_mat = np.float32(
[[1, 0, translation_x],
[0, 1, translation_y]]
)
rot_mat = cv2.getRotationMatrix2D( center, angle, zoom )
trans_mat = np.vstack([trans_mat, [0,0,1]])
rot_mat = np.vstack([rot_mat, [0,0,1]])
transformation_matrix = np.matmul(rot_mat, trans_mat)
img_0 = cv2.warpPerspective(
img_0,
transformation_matrix,
(img_0.shape[1], img_0.shape[0]),
borderMode=cv2.BORDER_WRAP
)
z, *_ = model.encode(TF.to_tensor(img_0).to(device).unsqueeze(0) * 2 - 1)
i += 1
z_orig = z.clone()
z.requires_grad_(True)
opt = optim.Adam([z], lr=args.step_size)
normalize = transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
pMs = []
for prompt in args.prompts:
txt, weight, stop = parse_prompt(prompt)
embed = perceptor.encode_text(clip.tokenize(txt).to(device)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for prompt in args.image_prompts:
path, weight, stop = parse_prompt(prompt)
img = resize_image(Image.open(path).convert('RGB'), (sideX, sideY))
batch = make_cutouts(TF.to_tensor(img).unsqueeze(0).to(device))
embed = perceptor.encode_image(normalize(batch)).float()
pMs.append(Prompt(embed, weight, stop).to(device))
for seed, weight in zip(args.noise_prompt_seeds, args.noise_prompt_weights):
gen = torch.Generator().manual_seed(seed)
embed = torch.empty([1, perceptor.visual.output_dim]).normal_(generator=gen)
pMs.append(Prompt(embed, weight).to(device))
def synth(z):
z_q = vector_quantize(z.movedim(1, 3), model.quantize.embedding.weight).movedim(3, 1)
return clamp_with_grad(model.decode(z_q).add(1).div(2), 0, 1)
def add_xmp_data(filename):
imagen = ImgTag(filename=filename)
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'creator', 'VQGAN+CLIP', {"prop_array_is_ordered":True, "prop_value_is_array":True})
if args.prompts:
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'title', " | ".join(args.prompts), {"prop_array_is_ordered":True, "prop_value_is_array":True})
else:
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'title', 'None', {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'i', str(i), {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'model', model_name, {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.xmp.append_array_item(libxmp.consts.XMP_NS_DC, 'seed',str(seed) , {"prop_array_is_ordered":True, "prop_value_is_array":True})
imagen.close()
def add_stegano_data(filename):
data = {
"title": " | ".join(args.prompts) if args.prompts else None,
"notebook": "VQGAN+CLIP",
"i": i,
"model": model_name,
"seed": str(seed),
}
lsb.hide(filename, json.dumps(data)).save(filename)
@torch.no_grad()
def checkin(i, losses):
losses_str = ', '.join(f'{loss.item():g}' for loss in losses)
tqdm.write(f'i: {i}, loss: {sum(losses).item():g}, losses: {losses_str}')
out = synth(z)
TF.to_pil_image(out[0].cpu()).save('progress.png')
add_stegano_data('progress.png')
add_xmp_data('progress.png')
display.display(display.Image('progress.png'))
def save_output(i, img, suffix=None):
filename = \
f"{working_dir}/steps/{i:04}{'_' + suffix if suffix else ''}.png"
imageio.imwrite(filename, np.array(img))
add_stegano_data(filename)
add_xmp_data(filename)
def ascend_txt(i, save=True, suffix=None):
out = synth(z)
iii = perceptor.encode_image(normalize(make_cutouts(out))).float()
result = []
if args.init_weight:
result.append(F.mse_loss(z, z_orig) * args.init_weight / 2)
for prompt in pMs:
result.append(prompt(iii))
img = np.array(out.mul(255).clamp(0, 255)[0].cpu().detach().numpy().astype(np.uint8))[:,:,:]
img = np.transpose(img, (1, 2, 0))
if save:
save_output(i, img, suffix=suffix)
return result
def train(i, save=True, suffix=None):
opt.zero_grad()
lossAll = ascend_txt(i, save=save, suffix=suffix)
if i % args.display_freq == 0 and save:
checkin(i, lossAll)
loss = sum(lossAll)
loss.backward()
opt.step()
with torch.no_grad():
z.copy_(z.maximum(z_min).minimum(z_max))
with tqdm() as pbar:
if iterations_per_frame == 0:
save_output(i, img_0)
j = 1
while True:
suffix = (str(j) if save_all_iterations else None)
if j >= iterations_per_frame:
train(i, save=True, suffix=suffix)
break
if save_all_iterations:
train(i, save=True, suffix=suffix)
else:
train(i, save=False, suffix=suffix)
j += 1
pbar.update()
except KeyboardInterrupt:
stop_on_next_loop = True
pass
動画の生成
生成したフレーム画像から動画を生成します。 この時、last_frameを指定することで、動画に使用するフレーム画像の範囲を指定できます。
# @title Create video
# import subprocess in case this cell is run without the above cells
import subprocess
# Try to avoid OOM errors
torch.cuda.empty_cache()
init_frame = 1#@param {type:"number"} This is the frame where the video will start
last_frame = 60#@param {type:"number"} You can change i to the number of the last frame you want to generate. It will raise an error if that number of frames does not exist.
fps = 12#@param {type:"number"}
try:
key_frames
except NameError:
filename = "video.mp4"
else:
if key_frames:
# key frame filename would be too long
filename = "video.mp4"
else:
filename = f"{'_'.join(text_prompts).replace(' ', '')}.mp4"
filepath = f'{working_dir}/{filename}'
frames = []
# tqdm.write('Generating video...')
try:
zoomed
except NameError:
image_path = f'{working_dir}/steps/%04d.png'
else:
image_path = f'{working_dir}/steps/zoomed_%04d.png'
cmd = [
'ffmpeg',
'-y',
'-vcodec',
'png',
'-r',
str(fps),
'-start_number',
str(init_frame),
'-i',
image_path,
'-c:v',
'libx264',
'-frames:v',
str(last_frame-init_frame),
'-vf',
f'fps={fps}',
'-pix_fmt',
'yuv420p',
'-crf',
'17',
'-preset',
'veryslow',
filepath
]
process = subprocess.Popen(cmd, cwd=f'{working_dir}/steps/', stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
if process.returncode != 0:
print(stderr)
print(
"You may be able to avoid this error by backing up the frames,"
"restarting the notebook, and running only the google drive/local connection and video synthesis cells,"
"or by decreasing the resolution of the image generation steps. "
"If these steps do not work, please post the traceback in the github."
)
raise RuntimeError(stderr)
else:
print("The video is ready")
Google Driveに動画が出力されます。
text_prompts = "'Moon': {10: 0, 60: 1}, 'Sun': {10: 1, 60: 0}"
initial_image = "/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg"
target_images = "'/content/drive/MyDrive/vqgan/images/yuka16011215IMG_5574_TP_V4.jpg': {10: 0, 60: 1}"
の出力結果は以下の通りです。

text_prompts = "'Death': {10: 0, 60: 1}
initial_image = "/content/drive/MyDrive/vqgan/images/nantoshi21PAR519902088_TP_V4.jpg"
target_images = ""
の出力結果は以下の通りです。
「死」を十字架やドクロで表現している点が興味深いですね。
まとめ
本記事では、VQGAN+CLIPを用いて機械学習でアニメーションを作ってみました。
SEED一つで出力結果が大きく変わるのでいろいろ試してみてください。
これを機に機械学習に興味を持つ方が一人でもいらっしゃいましたら幸いです。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. 論文 - Taming Transformers for High-Resolution Image Synthesis






0 件のコメント :
コメントを投稿