本記事では、6D Rotation Representation For Unconstrained Head Pose
Estimationを使用して、人物の頭の姿勢を推定する方法をご紹介します。
6DRepNet
概要
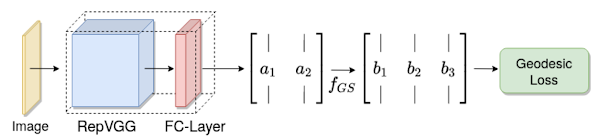
2022年2月に論文発表されたリアルタイムで人物の頭の姿勢を推定するHead Pose Estimation技術です。
Ground Truthデータに回転行列を適用し、6D回転行列表現とGeodesic
Lossの適用により、効率的でロバストな回帰ネットワークを構築しています。
このことにより、従来技術ではHead
Poseの予測を挟角のみに制限していましたが、この制限を取り払いつつ、6DRepNetは従来手法より最大20%の精度向上を実現しています。
詳細はこちらの論文をご確認ください。
本記事では、6DRepNetを用いてHead Pose Estimationする方法をご紹介します。
デモ(Colaboratory)
それでは、実際に動かしながら6DRepNetを用いたHead Pose
Estimationを行っていきます。
ソースコードは本記事にも記載していますが、下記のGitHubでも取得可能です。
GitHub - Colaboratory demo
また、下記から直接Google Colaboratoryで開くこともできます。

なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
環境セットアップ
それではセットアップしていきます。
Colaboratoryを開いたら下記を設定しGPUを使用するようにしてください。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
まず、GitHubからソースコードを取得します。
%cd /content
!git clone https://github.com/thohemp/6DRepNet
次にライブラリのインストール、インポートを行います。
%cd /content/6DRepNet
!pip install --upgrade gdown
!pip install git+https://github.com/elliottzheng/face-detection.git@master
from model import SixDRepNet
import math
import re
from matplotlib import pyplot as plt
import sys
import os
import argparse
import numpy as np
import cv2
from google.colab.patches import cv2_imshow
import matplotlib.pyplot as plt
from numpy.lib.function_base import _quantile_unchecked
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
import torch.backends.cudnn as cudnn
import torchvision
import torch.nn.functional as F
import utils
import matplotlib
from PIL import Image
import time
from face_detection import RetinaFace
import glob
from google.colab import files
from tqdm import tqdm
以上で、環境セットアップは完了です。
学習済みモデルのセットアップ
次に学習済みモデルのセットアップしていきます。
%cd /content/6DRepNet
!mkdir pretrained
#https://drive.google.com/file/d/1vPNtVu_jg2oK-RiIWakxYyfLPA9rU4R4/view?usp=sharing
pretrained_ckpt = 'pretrained/6DRepNet_300W_LP_AFLW2000.pth'
if not os.path.exists(pretrained_ckpt):
!gdown --id 1vPNtVu_jg2oK-RiIWakxYyfLPA9rU4R4 \
-O {pretrained_ckpt}
snapshot_path = os.path.join("/content/6DRepNet/", "pretrained/6DRepNet_300W_LP_AFLW2000.pth")
/content/6DRepNet/pretrainedにモデルがダウンロードされます。
テスト動画のセットアップ
Head Pose Estimationを行うテスト動画をアップロードします。
本記事ではこちらのPexels様の動画を使用させて頂きます。
%cd /content/6DRepNet
!rm -rf upload
!mkdir -p upload/frames
%cd upload
uploaded = files.upload()
uploaded = list(uploaded.keys())
file_name = uploaded[0]
upload_path = os.path.join("/content/6DRepNet/upload", file_name)
print("upload file here:", upload_path)
アップロードした動画をフレーム画像に分割します。
%cd /content/6DRepNet/upload
!ffmpeg -i {upload_path} frames/%06d.png
frames = glob.glob("/content/6DRepNet/upload/frames/*.png")
Head Pose Estimation
最後に動画から頭の姿勢を推定します。
%cd /content/6DRepNet
!rm -rf output
!mkdir -p output/frames
cudnn.enabled = True
gpu = 0
print("Start model setup...")
# Modelのビルド
model = SixDRepNet(
backbone_name='RepVGG-B1g2',
backbone_file='',
deploy=True,
pretrained=False)
detector = RetinaFace(gpu_id=gpu)
# Modelのロード
saved_state_dict = torch.load(os.path.join(snapshot_path), map_location='cpu')
if 'model_state_dict' in saved_state_dict:
model.load_state_dict(saved_state_dict['model_state_dict'])
else:
model.load_state_dict(saved_state_dict)
model.cuda(gpu)
# Test the Model
model.eval() # Change model to 'eval' mode (BN uses moving mean/var).
print("Complete model setup.")
print("loading ", len(frames), " frames...")
process_start = time.time()
with torch.no_grad():
for i in tqdm( range(len(frames)) ):
img_path = frames[i]
frame = np.array(Image.open(img_path))
faces = detector(frame)
for box, landmarks, score in faces:
# Print the location of each face in this image
if score < .95:
continue
x_min = int(box[0])
y_min = int(box[1])
x_max = int(box[2])
y_max = int(box[3])
bbox_width = abs(x_max - x_min)
bbox_height = abs(y_max - y_min)
x_min = max(0,x_min-int(0.2*bbox_height))
y_min = max(0,y_min-int(0.2*bbox_width))
x_max = x_max+int(0.2*bbox_height)
y_max = y_max+int(0.2*bbox_width)
img = frame[y_min:y_max,x_min:x_max]
img = cv2.resize(img, (244, 244))/255.0
img = img.transpose(2, 0, 1)
img = torch.from_numpy(img).type(torch.FloatTensor)
img = torch.Tensor(img).cuda(gpu)
img=img.unsqueeze(0)
start = time.time()
R_pred = model(img)
end = time.time()
#print('Head pose estimation: %2f ms'% ((end - start)*1000.))
euler = utils.compute_euler_angles_from_rotation_matrices(R_pred)*180/np.pi
p_pred_deg = euler[:, 0].cpu()
y_pred_deg = euler[:, 1].cpu()
r_pred_deg = euler[:, 2].cpu()
utils.plot_pose_cube(frame, y_pred_deg, p_pred_deg, r_pred_deg, x_min + int(.5*(x_max-x_min)), y_min + int(.5*(y_max-y_min)), size = bbox_width)
# 1フレーム完了毎に表示する場合はコメントアウト解除
#cv2_imshow(frame)
cv2.imwrite( os.path.join("/content/6DRepNet/output/frames", os.path.basename(img_path)), frame)
process_end = time.time()
print('Complete All Head pose estimation: %2f s'% (process_end - process_start))
print('Average %2f ms/ %06d frames'% (((process_end - process_start)*1000.)/len(frames), len(frames)))
推定結果はフレーム画像にオーバーレイされて出力されます。
処理速度は以下の通りです。
/content/6DRepNet
Start model setup...
Complete model setup.
loading 239 frames...
100%|██████████| 239/239 [00:24<00:00, 9.85it/s]Complete All Head pose estimation: 24.276616 s
Average 101.575799 ms/ 000239 frames
次に、フレーム画像から動画を生成します。
!ffmpeg -i "/content/6DRepNet/output/frames/%06d.png" -c:v libx264 -vf "format=yuv420p" "/content/6DRepNet/output/result.mp4"
最後に、動画を出力します。
from moviepy.editor import *
from moviepy.video.fx.resize import resize
clip = VideoFileClip("/content/6DRepNet/output/result.mp4")
clip = resize(clip, height=420)
clip.ipython_display()
出力結果は以下の通りです。
高速かつ、正確に頭の姿勢を推定できています。
まとめ
本記事では、6DRepNetを用いてHead Pose Estimationする方法をご紹介しました。
高速なため、ある程度のGPUであればカメラでキャプチャしながらリアルタイムに推定も可能です。
これを機に機械学習に興味を持つ方が一人でもいらっしゃいましたら幸いです。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
リンク
リンク
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1.
論文 -6D Rotation Representation For Unconstrained Head Pose Estimation
2. GitHub - thohemp/6drepnet








0 件のコメント :
コメントを投稿