本記事では、CapDecと呼ばれる機械学習手法を用いて、任意の画像のキャプションを生成する方法をご紹介します。
 |
| 出典: DavidHuji/CapDec |
CapDec
概要
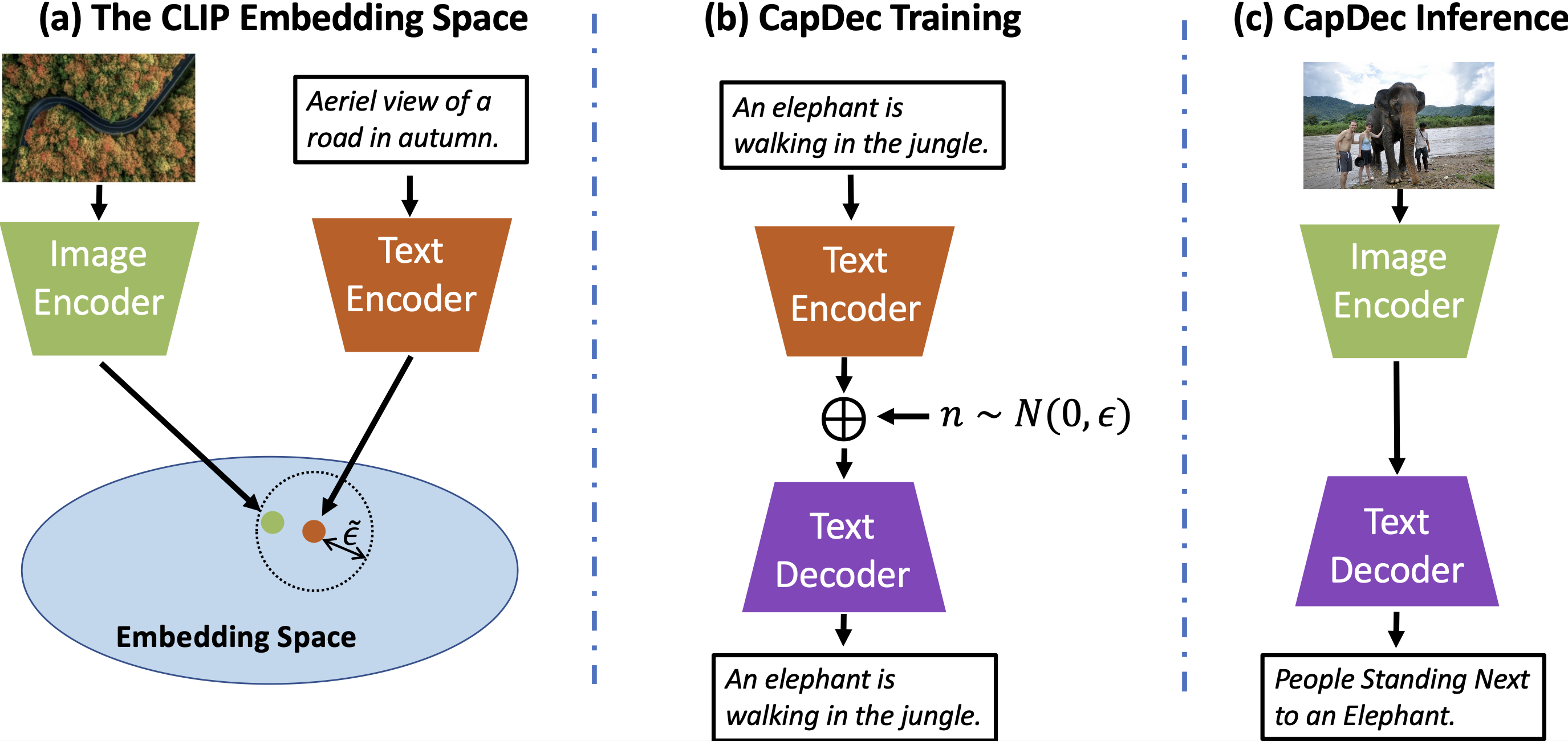
CapDecは、画像を入力し、画像の説明文となるキャプションを生成するImage captioning技術です。
CapDecは、トレーニング時にCLIPモデルと追加のテキストデータのみを使用し、キャプション付き画像を必要としません。
このアプローチは、CLIPが視覚的なembeddeingとテキストのembeddingを類似させるようにトレーニングされていることに基づき、CapDecはテキストembeddingをテキストに変換する方法をトレーニングさせることによりImage captioningを実現しています。
論文中では、このアプローチが4つのベンチマークで最先端の精度を達成していると示されています。
 |
| 出典: Text-Only Training for Image Captioning using Noise-Injected CLIP |
詳細はこちらの論文をご参照ください。
本記事では上記手法を用いて、任意の画像からキャプションを生成していきます。
デモ(Colaboratory)
それでは、実際に動かしながらImage captioningタスクを試していきます。
ソースコードは本記事にも記載していますが、下記のGitHubでも取得可能です。
GitHub - Colaboratory demo
また、下記から直接Google Colaboratoryで開くこともできます。
![]()
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
環境セットアップ
それではセットアップしていきます。 Colaboratoryを開いたら下記を設定しGPUを使用するようにしてください。
初めににライブラリをインストールします。
続いて、CapDecにキャプションを生成させる画像をStable Diffusionで生成するためアクセストークンを設定します。
Stable Diffusionのアクセストークン取得方法は以下をご覧ください。
[Stable Diffusion] AIでテキストから画像を生成する[text2img]
本記事では、機械学習手法Stable Diffusionを用いてテキストから画像を生成する方法をご紹介しています。
最後にライブラリをインポートします。
以上で環境セットアップは完了です。
学習済みモデルのセットアップ
ここでは、Image captioningの事前学習済みをダウンロードします。
Text to Image
ここではまず、CapDecに入力する画像をStable Diffusionで生成していきます。
テキストA man and a woman posing for a picture next to tokyo tower.を入力し、画像を生成します。
Stable Diffusionが生成した画像は以下の通りです。
東京タワーらしき建物が2棟立っています。

Image captioning
それでは、本題のCapDecによるImage captioningを動かしていきます。
まず、モデルをロードします。
ロードしたCapDecを用いて、キャプションを生成していきます。
出力結果は以下の通りです。
直訳すると高層ビルの隣の桟橋の上に立っている 2 人の人々が出力されました。
東京タワーとはキャプションされませんでしたが、概ね意味の通るキャプションが生成されています。
Image captioning to Image
最後におまけとして、キャプションを入力に、再度Stable Diffusionで画像を生成してみます。
出力結果は以下の通りです。

キャプションを反映して桟橋ギリギリに立つ2人の画像が生成されています。
まとめ
本記事では、CapDecを用いて任意の画像からキャプションを生成する方法をご紹介しました。
精度向上と共に、データセットの自動生成などにも活用できそうです。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. 論文 - Text-Only Training for Image Captioning using Noise-Injected CLIP






0 件のコメント :
コメントを投稿