DX(デジタルフォーメーション)と共に、業務効率化と言えばAIOCRというほど、近年目に触れる機会が増えたAIOCR。本記事では、AIOCRを実現する技術要素を解説しながら、AIOCRの仕組みを紹介します。また実際に動かすことのできるソースコードを紹介します
AIOCRとOCRの違い
従来のOCRとは
従来のOCR技術は主にパターンマッチングによって実現されていました。
パターンマッチングにも様々な手法が存在しますが、大まかにはOCRモジュールがそれぞれの文字のパターンを保有しており、判別対象文字と保有するパターンを照らし合わせることによって文字を判別していました。
従来のOCR技術でも、文字の形状が比較的類似している活字の判別は高精度で判断できていました。
一方で、書き方が千差万別な手書き文字の判別の精度は高精度とは言えるものではありませんでした。
書き方が人によってバラバラな手書き文字のパターンを全て把握することは現実的に困難であったためです。
AIOCRとは
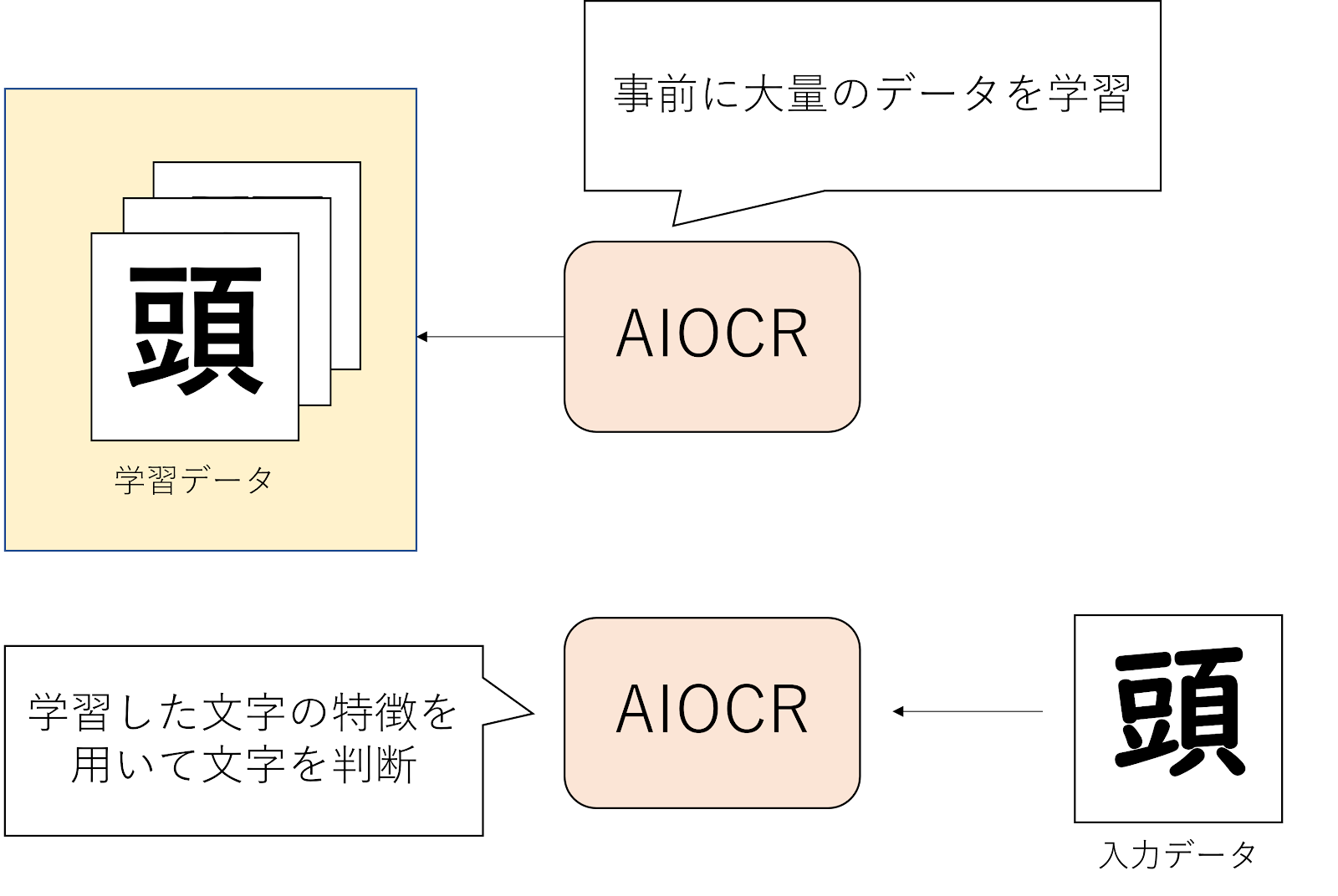
一方でAIOCRは、機械学習(特にディープラーニング)によって実現されています。
AIOCRは、パターンではなく学習によって得られた文字毎の特徴を用いて文字を予測しています。
従来のAIOCRより、抽象的で高次元な判断を行います。
そして、大量の手書き文字を学習することによって、手書き文字のバラツキを加味しながらそれぞれの文字の特徴を理解するAIOCRは、
従来のOCRより高精度に判別することが可能になりました。
ただし、AIは万能ではありません。文字を判別するためには事前に学習している必要があります。このため事前に学習していない文字は判別できません。
また活字文字だけを学習したAIOCRでは、手書き文字を高精度に判別することはできません。手書き文字を高精度に判別するためには手書き文字を大量に学習している必要があります。
このような背景から、AIOCRを提供しているベンダーごとに活字や記号を得意とするベンダーや、手書き文字の精度を特徴としているベンダーなど各社に特徴があります。AIOCRベンダーを選定する際には、料金と共に、得意とする文字もご確認ください。
AIOCRの技術要素
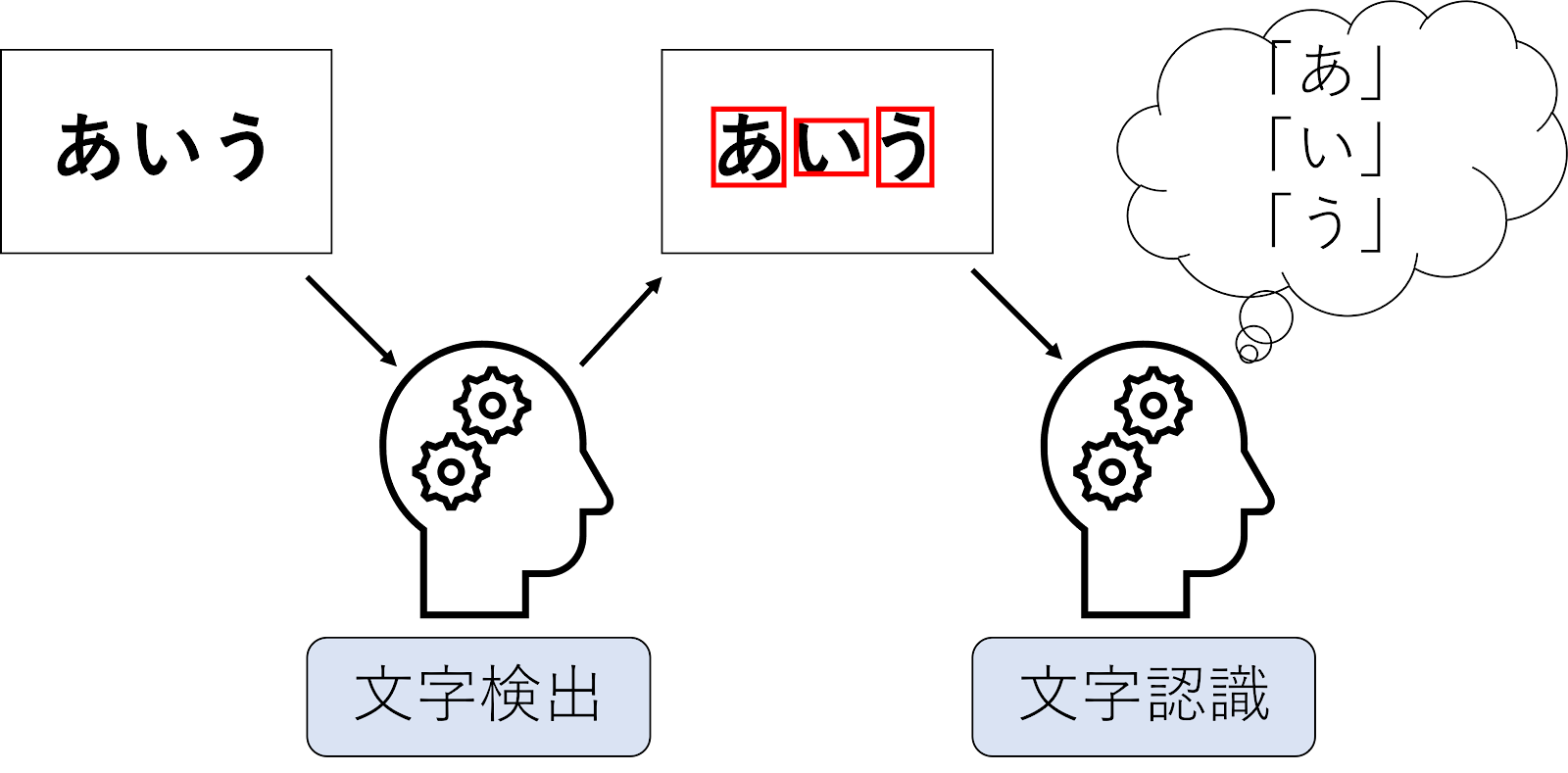
AIOCRは、主に「文字検出」と「文字認識」の2つの技術要素によって実現されています。
文字検出
文字検出では、画像中の文字の場所を検出します。
文字検出には、2パターンの検出方法が存在します。
それは、単語ごとに検出する方法と、1文字ごとに検出する方法です。
英語のように単語ごとに明確な空白が生じる言語は単語ごとに検出し、
日本語のように単語ごとに明確な空白がない場合は文字毎に検出する傾向にあります。

|
|
1文字ごとに検出する文字検出
|

|
|
テキストごとに検出する文字検出
|
この日本語と英語の検出方法の違いは
言語構成の違いと、文字種の多さに起因しています。
文字検出を学習させる際の学習データは、選択するモデルによって細かなデータ形式は異なりますが、ほとんどが画像データと、文字の場所を示す座標を学習データとして与えます。
例えば先ほどの「This is a
pen」の画像を学習させる場合は下記のような座標をモデルに学習させます
[
[x1, y1, width1, height1], # this
[x2, y2, width2, height2], # is
[x3, y3, width3, height3], # a
[x4, y4, width4, height4], # pen
]
この座標をデータとして作成する場合、英語の場合は単語ごとに明確に区切りが存在するため、容易に不特定多数の人が"単語ごとに区切る"というルールに基づいて学習データを作成できます。
一方で、日本語の場合、このような視覚的に見てわかる"単語ごとに区切る"といったルールが存在しません。このため、学習データの品質を一定に保つことを考えると、一文字ごとに区切らざるを得ないと言えます。
また、行ごとに検出するように学習させることも可能ですが、
この場合、後継の文字認識で行ごとに検出された画像の文字を認識する必要があります。
一般的に、一度に複数文字を認識しようとすればするほどその文字認識率は下がっていきます
英語であれば、文字種もアルファベットと数字、記号を含めても100文字以下であるため
単語ごとに認識する場合であってもその組み合わせの数は十分現実的な学習データ量で補うことが可能です。
一方で日本語は、常用漢字だけでも2000文字を超えます。
これらを組み合わせて作られる単語や、まして1行の文の組み合わせはほぼ無限に近い値となります。これを学習させていくこと効率的ではありません。
つまり、文字認識率の確保を考えると日本語は1文字ずつ検出した方が良いことが分かります。
文字認識
検出した文字領域から画像を抽出し、画像に含まれる文字を判別することを文字認識と言います。
単語ごとに文字検出している場合は、一単語が切り取られた画像に対して文字認識を実行します。
一方で、一文字ごとに検出している場合は、一文字のみが切り取られた画像に対して
文字認識を実行します。
文字認識とは、認識対象の文字を見て、AIが持ち合わせる文字の候補のどれかに分類しているだけなのです。
AIOCRの構成
AIOCRを実現する構成には大別して2パターン存在します。
2 stage model
読んで字のごとく二つのモデルでAIOCRを実現する手法です
文字検出と文字認識をそれぞれ別のモデルを使って実現します
End to End model
一つのモデルでAIOCRを実現する手法です
文字検出と文字認識を一つのモデルを使って実現します
論文によってはText Spottingと表現される場合もあります。
最新動向
arXivに掲載されたOCR関連の論文を調査したところ、近年はEnd to End
modelが増加傾向にあります
一般的にEnd to End
modelは、「文字検出」と「文字認識」の2つのタスクを同時に学習、予測するため、CPU、GPUやメモリなど多くのハードウェアリソースを必要とします。
しかし、GPUの性能向上やハードウェアリソースの向上に伴い
膨大な特徴量を持つ学習が現実的な時間で実行可能になったためと考えられます。
また、これは2 stage modelの技術が成熟しつつあることも理由として考えられます。
2 stage model と End to End modelの比較
学習時間
2stage modelは文字検出と文字認識をそれぞれ別に学習します
このためEnd to Endと比較し学習する特徴量が少ない傾向にあります
結果として学習時間はEnd to End modelより短くなる傾向にあります
学習時メモリ使用量
学習時のバッチサイズに左右されますが、
End to End modelの方がメモリ使用量が多い傾向が強いです
特に、GEFORCE GTX 1080のようなGPUメモリが10GB以下のGPUではOut Of
Memoryが発生する場合もあります
お手持ちの開発環境にもよりますがEnd to End modelの学習が厳しい場合もあります
論文およびソースコード
ここではソースコードが公開された論文を紹介します
下記に記載のソースコードは全てPythonでコーディングされています。
Pythonに不安がある方はこちらの書籍などがおすすめです。
リンク
2stage model - 文字検出
2017年7月
2019年4月
2019年12月
それぞれの手法の選択は下記ベンチマークが参考になります
出典: https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/algorithm_overview_en.md
2stage model - 文字検出
2019年10月
それぞれの手法の選択は下記ベンチマークが参考になります
出典: https://github.com/clovaai/deep-text-recognition-benchmark
End to End model
2018年1月
2020年7月
2020年10月
End to Endは最新手法ほど学習済みモデルのサイズが大きくなっています。
AE
TextSpotterは中国で開発されていることもあり、縦書き、横書きの判別のため自然言語処理も組み込まれています。
日本語への転用も可能ですが、学習時間、消費メモリ共に莫大であるため機械学習専用のハードウェアがないと学習は厳しくなります。
まとめ
AIOCRを構成する技術要素である「文字検出」と「文字認識」について解説し、
論文やソースコードを紹介させて頂きました。
AIOCRを動かしてみたい方がいらっしゃいましたら2 stage
modelから試してみることをお勧めします。比較的ソースコードが簡潔であり、必要なハードウェアリソースも少ないため学習目的には最適です。
また本記事では、AIOCRにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
リンク
リンク
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。












0 件のコメント :
コメントを投稿