Microsoftが提供するTransformerベースのOCRであるTrOCRの導入手順を解説します。

TrOCRとは
TrOCRとはMicrosoftが発表したTransformerベースのOCRです。[参考:arxiv]
従来のAIOCRは、画像中の文字を検出する文字検出にCNNを、文字認識にRNNを適用してモデルを構築することが一般的でした。
一方でTrOCRでは文字検出と文字認識共に、Transformerを適用しています
Transformerを適用することによる利点は下記3点であると論文で語られています。
- 事前にトレーニングされたImageTransformerモデルと、TextTransformerモデルを使用し、精度を確保
- バックボーンに畳み込みネットワークを必要としないためモデルの実装と保守の簡素化
- OCRのベンチマークデータセット(IAM(手書き)/SROIE(活字))にて最先端の精度
簡単にまとめると、Transformerの適用により、事前学習済みモデルによって精度を確保し、モデルが簡素になっているOCRであると言えそうです。
一方でデメリットとしては、モデルのサイズが大きくなりがちといったところでしょうか?
提供されているTrOCR-Large-IAMは6.4GBにも及びます。

|
|
TrOCRの概念図 出典:https://arxiv.org/pdf/2109.10282.pdf |
TrOCRの導入手順
TrOCRのセットアップ手順
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
それでは、TrOCRをインストールしていきます。他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
TrOCRはmicrosoftが提供するUniLM AIというプロジェクトの一つです。
UniLM
AIは要約抽出や、OCR、翻訳などの様々な事前トレーニング済みモデルを提供しているGitのプロジェクトです。
以上で、TrOCRのセットアップは完了です。
続いてTrOCRの学習済みモデルを使って文字認識していきます。
TrOCRで文字認識
学習済みモデルが公開されているため、このモデルを使って手書き英語の文字認識していきます。
なお、学習済みモデルが非常に大きいためダウンロードに時間がかかります。(およそ20分)
今回は以下のような手書き英語の公開データセットを用意しました。
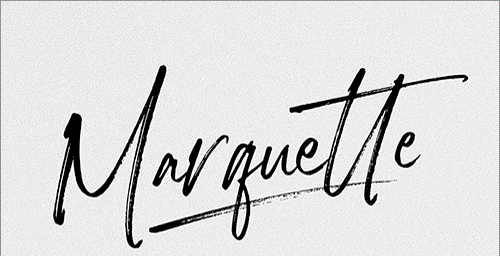
それでは、文字認識を実行していきます。
trocr/pic_inference.pyにtest用画像とモデルのパスを設定します。
trocr/pic_inference.pyをpython3 pic_inference.pyで実行します
いかがですか?概ね認識されているかと思います。
urllib.error.HTTPError: HTTP Error 404: Not Found
もし、以下のような404エラーが出力される場合は、ベースとなるモデルのロードに失敗しています。
下記の通り、ローカルにモデルをダウンロードしておき、ファイルを修正することで解消します。
まとめ
本記事ではTransformerベースのOCRであるTrOCRを紹介させて頂きました。
ソースコードをクローンしていただくと分かりますが、コードの量が非常に少ないことが分かります。一方で、モデルサイズが1GBを超え非常に巨大であることも分かります。
CNN, RNNなどを必要としないためコードが簡素であるため見通しが良く、
どこでどのような処理を行っているか確認しやすい点が良いですね。
一方で、モデルが非常に大きいため、組み込み機器等、ハードウェア制約がある環境では、動作困難な可能性があります。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models






0 件のコメント :
コメントを投稿