Salesforceが提供する時系列データの機械学習ライブラリであるMerlionの導入方法、及び、異常検知、予測の実施手順を解説します。
Merlionとは
Salesforceが開発する時系列データの機械学習Pythonライブラリです。
データの読み込み、変換、モデルの構築、モデル出力の後処理、モデルパフォーマンス評価など時系列データの機械学習に必要な機能全般を備えています。
単変量と多変量の時系列データの予測(forecasting)と異常検出(anomaly
detection)など、時系列学習タスクをサポートしています。
また下記の特徴を備えています。
-
時系列データの幅広いデータセットに対する標準化された拡張容易なデータ読込機能
-
古典的統計手法、ツリーアンサンブル、ディープラーニング手法をサポート
- 初学者のために抽象化された予測、異常検知モデルを用意
- モデル選択、ハイパーパラメータ調整を自動化するAutoML
- 実用的な異常検出タスクの後処理
- 使いやすいアンサンブル機能
- パフォーマンス評価パイプライン
- モデルの可視化機能
他の時系列ライブラリとの機能比較表は下記となります。後発である分、サポート範囲は広いと言えそうです。

|
|
出典: https://github.com/salesforce/Merlion
|
Merlionの導入手順
それでは、Merlionをインストールしていきます。他の機械学習環境に影響を与えないためにMinicondaの仮想環境上に構築していきます。Minicondaのインストール手順は公式ドキュメントをご参照ください。
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
それではMerlionをインストールしていきます。
# 一部の異常検出モデルが、Java Development Kit(JDK)に依存しているためopenjdk-11-jdkをインストール
$ sudo apt-get install openjdk-11-jdk
# conda環境作成
$ conda create -n merlion_test python=3.7 jupyter
# conda環境アクティベート
$ conda activate merlion_test
# 一部の予測モデルが、OpenMPに依存しているためlightgbmをインストール
$ conda install -c conda-forge lightgbm
# 作業用ディレクトリ作成
$ cd merlion_test
$ mkdir workspace
$ cd workspace
# Merlioneをgit clone
$ git clone https://github.com/salesforce/Merlion.git
$ cd Merlion
# pip install
$ pip3 install -e .
# Proxy配下の場合は下記でpip install
$ pip3 install -e . --proxy=http://"username":"password"@proxy:port
# 可視化に関するライブラリをpip install
$ pip3 install ".[plot]"
# Proxy配下の場合は下記でpip install
$ pip3 install ".[plot]" --proxy=http://"username":"password"@proxy:port
# データロードに関するパッケージをpip install
$ pip3 install -e ts_datasets/
# Proxy配下の場合は下記でpip install
$ pip3 install -e ts_datasets/ --proxy=http://"username":"password"@proxy:port
以上でMerlionの導入は完了です。
異常検知(Anomaly Detection)
Merlionを使って異常検知タスクを動かしていきます。
データの読み込み
はじめに、NABのrealKnownCauseと呼ばれるデータセットから「machine_temperature_system_failure.csv」を読み込みます。
# file名: anomaly_detection_test.ipynb
from merlion.utils import TimeSeries
from ts_datasets.anomaly import NAB
# Proxy配下の場合下記のコメントを外す
# os.environ["http_proxy"] = "http://"username":"password"@proxy:port"
# os.environ["https_proxy"] = "http://"username":"password"@proxy:port"
# データローダーからrealKnownCauseを取得し、温度センサーデータのみ抽出
time_series, metadata = NAB(subset="realKnownCause")[3]
# pandas DataFramesをMerlionのTimeSeriesに変換
# 学習データとテストデータに分割
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
test_labels = TimeSeries.from_pd(metadata.anomaly[~metadata.trainval])
下記の形式のデータをロードしました。test_dataはタイムスタンプと温度データです。
test_data
test_labelsはタイムスタンプと異常であることを示すラベルが付与されています。0.0は異常なしを示しています。
test_labels
学習
次にDefaultDetectorを使ってtrain_dataを学習します。
from merlion.models.defaults import DefaultDetectorConfig, DefaultDetector
# DefaultDetectorモデルのセット
model = DefaultDetector(DefaultDetectorConfig())
# Train
model.train(train_data=train_data)
# 異常検知結果取得
test_pred = model.get_anomaly_label(time_series=test_data)
予測結果の可視化
学習したモデルを使ってtest_dataを異常検知し、その結果を可視化します。
from merlion.plot import plot_anoms
import matplotlib.pyplot as plt
# 異常検知予測結果の可視化
fig, ax = model.plot_anomaly(time_series=test_data)
plot_anoms(ax=ax, anomaly_labels=test_labels)
plt.show()
以下の予測結果のグラフが出力されます。
Anomaly Scoreが突出している3か所が異常検知された箇所です。
赤い帯状の箇所が実際の異常箇所です。
このため2か所の検出に成功し、1か所の検出に失敗していることが分かります。
モデルの評価
次に、モデルを評価します。以下の実装では、適合率(Precision)、再現率(Recall)、F値(F1)の3つを算出しています。また、平均検出時間(Mean
Time To Detect: MTTD)も併せて算出します。
また適合率、再現率、F値や、平均検出時間に関しては参考文献3.
4.のリンクをご参照ください。
from merlion.evaluate.anomaly import TSADMetric
# 適合率(Precision)
p = TSADMetric.Precision.value(ground_truth=test_labels, predict=test_pred)
# 再現率(Recall)
r = TSADMetric.Recall.value(ground_truth=test_labels, predict=test_pred)
# F値(F1)
f1 = TSADMetric.F1.value(ground_truth=test_labels, predict=test_pred)
# 平均検出時間(Mean Time To Detect: MTTD)
mttd = TSADMetric.MeanTimeToDetect.value(ground_truth=test_labels, predict=test_pred)
print(f"Precision: {p:.4f}, Recall: {r:.4f}, F1: {f1:.4f}\n"
f"Mean Time To Detect: {mttd}")
# 出力結果
# Precision: 0.6667, Recall: 0.6667, F1: 0.6667
# Mean Time To Detect: 1 days 10:30:00
予測(Forecasting)
続いてMerlionを使って予測タスクを実施していきます。
データの読み込み
始めにM4と呼ばれるデータセットから時系列データに関するデータセットを取得します。
# file名: forecasting_test.ipynb
from merlion.utils import TimeSeries
from ts_datasets.forecast import M4
# Proxy配下の場合下記のコメントを外す
# os.environ["http_proxy"] = "http://"username":"password"@proxy:port"
# os.environ["https_proxy"] = "http://"username":"password"@proxy:port"
# データローダーからM4 Hourlyを取得し、0番目のサンプルデータのみ抽出
time_series, metadata = M4(subset="Hourly")[0]
# pandas DataFramesをMerlionのTimeSeriesに変換
# 学習データとテストデータに分割
train_data = TimeSeries.from_pd(time_series[metadata.trainval])
test_data = TimeSeries.from_pd(time_series[~metadata.trainval])
下記の形式のデータをロードしました。test_dataはタイムスタンプとValueです。
test_data
学習
次にDefaultForecasterを使ってtrain_dataを学習します。
from merlion.models.defaults import DefaultForecasterConfig, DefaultForecaster
# DefaultForecasterモデルのセット
model = DefaultForecaster(DefaultForecasterConfig())
# 学習
model.train(train_data=train_data)
# 予測
test_pred, test_err = model.forecast(time_stamps=test_data.time_stamps)
予測結果の可視化
学習したモデルを使ってtest_dataを予測し、その結果を可視化します。
import matplotlib.pyplot as plt
# forecast結果をplot
fig, ax = model.plot_forecast(time_series=test_data, plot_forecast_uncertainty=True)
# 表示
plt.show()
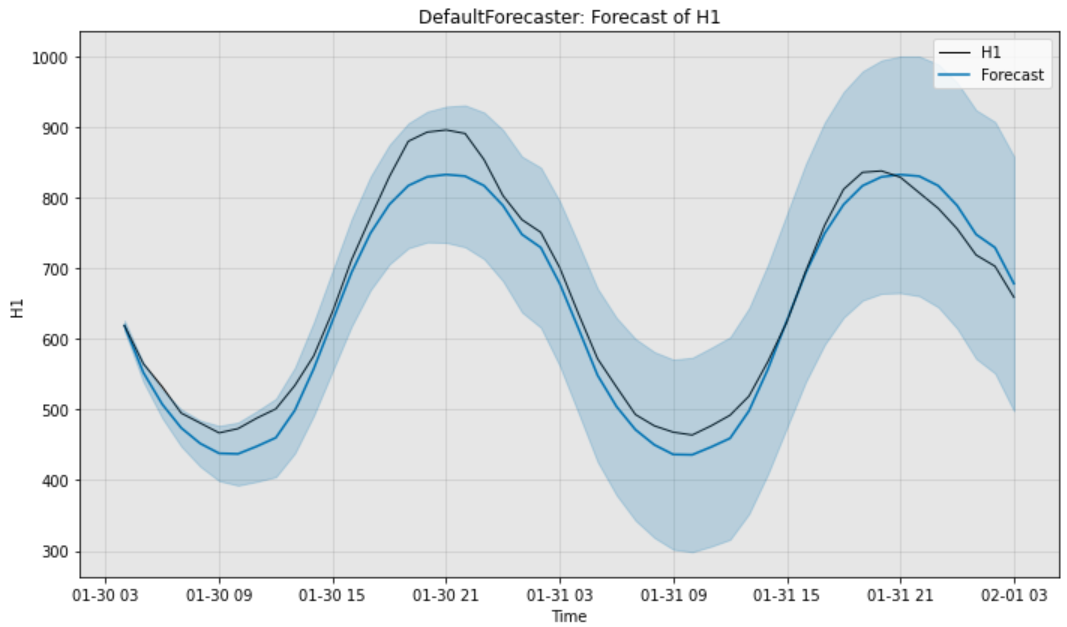
H1が実際の値で、Forecastが予測された値です。
モデルの評価
次に、モデルを評価します。以下の実装では、対称平均絶対パーセント誤差(sMAPE)で予測と実測値の誤差を算出し、Mean
Scaled interval
score(MSIS)で特定の信頼区間の品質を評価しています。どちらの評価指標も値が低いほど精度の高いモデルであることを示します。
from scipy.stats import norm
from merlion.evaluate.forecast import ForecastMetric
# Compute the sMAPE of the predictions (0 to 100, smaller is better)
# sMAPE算出(0~100, 低いほど高精度)
smape = ForecastMetric.sMAPE.value(ground_truth=test_data, predict=test_pred)
# Compute the MSIS of the model's 95% confidence interval (0 to 100, smaller is better)
# MSIS算出(0~100, 低いほど高精度)
lb = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.025) * test_err.to_pd().values)
ub = TimeSeries.from_pd(test_pred.to_pd() + norm.ppf(0.975) * test_err.to_pd().values)
msis = ForecastMetric.MSIS.value(ground_truth=test_data, predict=test_pred,
insample=train_data, lb=lb, ub=ub)
print(f"sMAPE: {smape:.4f}, MSIS: {msis:.4f}")
# 出力結果
# sMAPE: 4.1944, MSIS: 19.2679
まとめ
本記事では、Merlionの導入方法と、Merlionを使った異常検知と予測の実施手順を紹介しました。
いかがだったでしょうか?
想像していたよりも、かなり少ないコード量で実現できることがお判りいただけたかと思います。
今回紹介した機能はMerlionの基本的な振る舞いのみですが、おおよその処理の流れは掴んでいただけたかと思います。
AIの世界は日進月歩の世界です。1年で予測精度や学習速度が大きく変わるような手法が発表されていたりします。
日々、最新動向を把握し、使えそうな技術があればひとまず試してみると良いかもしれません。
また本記事では、Deep Learningを動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
リンク
リンク
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. Github - salesforce/Merlion
2. Welcome to Merlion’s documentation!
3. 【初心者向け】 機械学習におけるクラス分類の評価指標の解説
4. 平均修復時間(MTTR)とは? - MTBFとの違いや計算方法
5. Symmetric mean absolute percentage error










0 件のコメント :
コメントを投稿