本記事では、Meta(旧 facebook)発表のOmnivoreを使って画像分類・動画分類する方法を紹介します。

Omnivore
概要
Omnivoreは、まったく同じモデルパラメータを使用して画像・動画・シングルビュー3Dを分類する技術です。
従来技術では、画像では画像専用の、動画は動画専用の、シングルビュー3Dはシングルビュー3D専用のそれぞれ個別のモデルを生成していました。
Meta(旧facebook)が発表したOmnivoreは、これらの入力データを単一のモデルで分類可能にしました。
まさしくOmnivore(雑食動物)ですね。
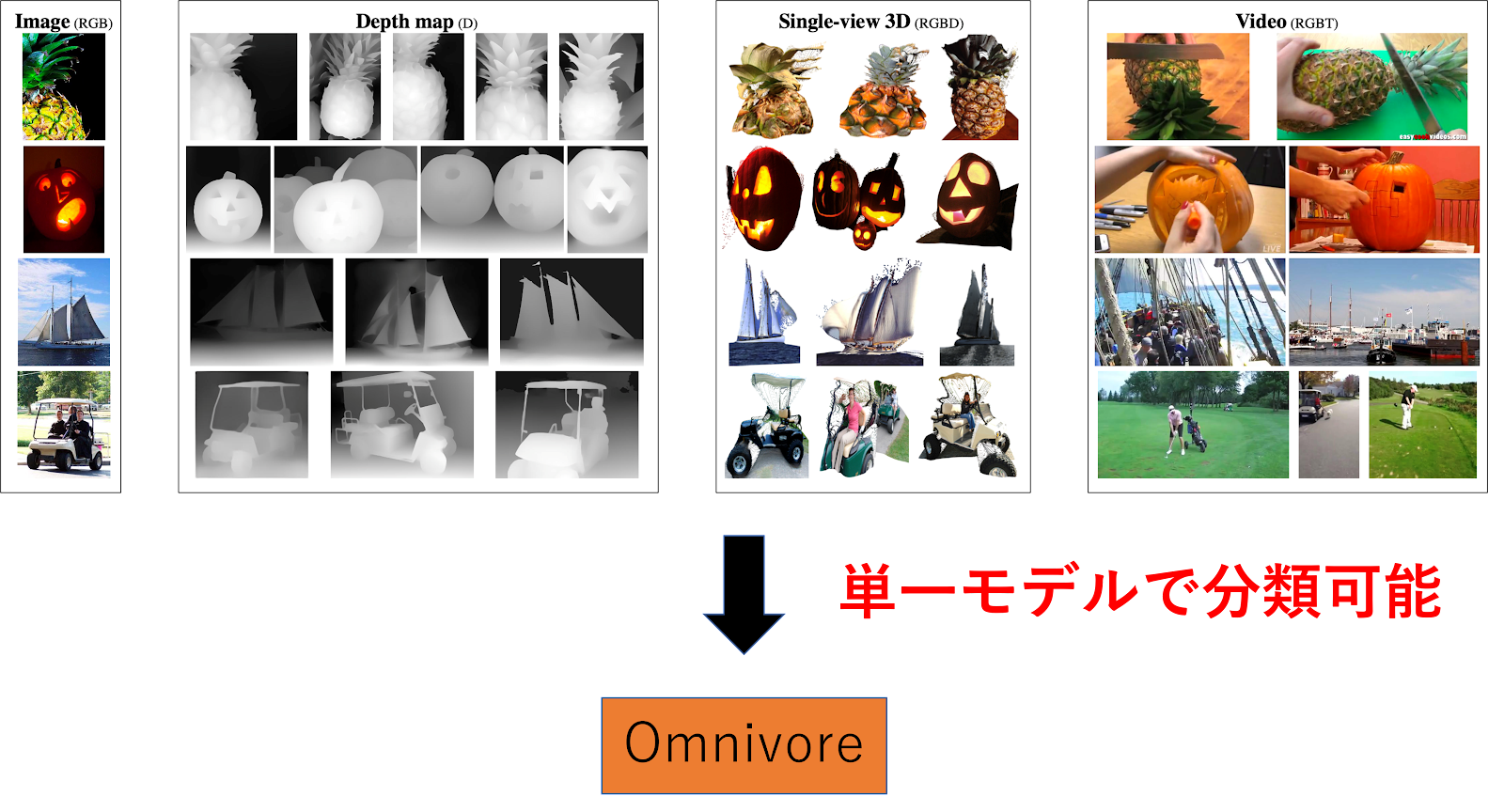
さらに、単一のモデルで分類が可能でありながら、従来のそれぞれ専用のモデルと同等かそれ以上のパフォーマンスを発揮します。
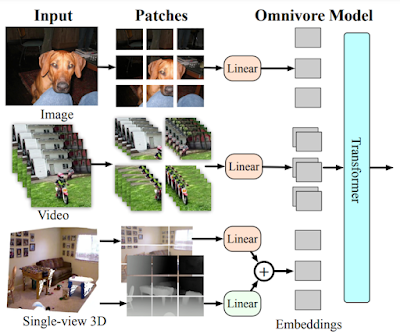
|
| 出典: OMNIVORE: A Single Model for Many Visual Modalities |
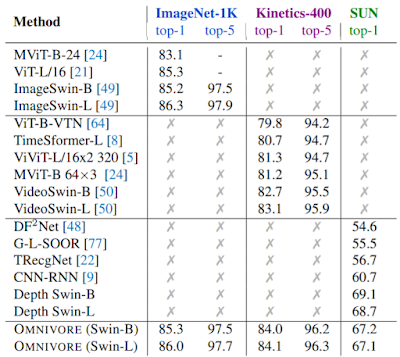
|
| 出典: OMNIVORE: A Single Model for Many Visual Modalities |
デモ(Colaboratory)
それでは早速OmnivoreをGoogle Colaboratoryで動かしていきます。
なお、これから紹介するソースコードは全てこちらのGitHubに掲載しております。以下のボタンをクリックするとColaboratoryを開くことも可能です。
なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
環境セットアップ
まず、Pytorchや、その他ライブラリをインストールします。
ColaboratoryにはデフォルトでPytorch1.10.0がインストールされていますが、Omnivoreの推奨バージョンが1.9.0のためPytorchをインストールし直しています。
モデルのロード
以下でモデルをロードしています。
omnivoreのmodel zooに学習済みモデルの一覧があります。本記事ではOmnivore Swin Bを使用します。
画像分類
それでは、画像分類を行っていきます。本記事ではこちらのフリー画像を使用します。

画像分類結果は以下の通りです。
上位5番目までの検出ラベル
ラベル: analog_clock , Score: 0.893880307674408
ラベル: wall_clock , Score: 0.002243553986772895
ラベル: chain , Score: 0.001472137519158423
ラベル: Band_Aid , Score: 0.0013656836235895753
ラベル: digital_clock , Score: 0.0009382738498970866
アナログ時計の最もスコアが高い結果となりました。画像を正確に分類できていますね。
一点注意点ですが、次の動画分類で10GBほどRAMを消費します。Colaboratory環境ですと結構RAMがカツカツになるため使用済みのデータは適宜削除しています。
動画分類
続いて動画分類を行います。
単一モデルで分類が可能であるためモデルを再びロードする必要はありません。
本記事では、こちらのフリー動画を使用します。

上位5番目までの検出ラベル
ラベル: feeding birds , Score: 0.8616467714309692
ラベル: watering plants , Score: 0.00801265612244606
ラベル: walking the dog , Score: 0.001959798391908407
ラベル: dining , Score: 0.0017679614247754216
ラベル: smoking , Score: 0.0015188349643722177
鳥の餌やりが最も高いスコアとなりました。鳥であることは分類されていますね。
シングルビュー3D画像分類
最後にシングルビュー3D画像分類を行います。
本記事では、こちらの画像を使用します。

シングルビュー3D画像分類結果は以下の通りです。
上位5番目までの検出ラベル
ラベル: furniture_store , Score: 0.8616467714309692
ラベル: bedroom , Score: 0.00801265612244606
ラベル: bathroom , Score: 0.001959798391908407
ラベル: rest_space , Score: 0.0017679614247754216
ラベル: office , Score: 0.0015188349643722177
furniture_store(家具屋)が最も高いスコアとなりました。この画像はIKEAの店内の画像なので正しく分類できています。
まとめ
本記事では、Omnivoreと呼ばれる機械学習手法を利用し、単一モデルで画像分類・動画分類・シングルビュー3D画像分類を行う方法を紹介しました。
一つのモデルで様々な分類が可能になることにより、モデルを切り替える必要がなくなりシステム全体の実行速度が向上したり、保存するモデル数が減ることによりディスク容量削減や、モデルアップデート等の管理コストの削減等が見込めますね。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
機械学習について学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。






{kind=link}
0 件のコメント :
コメントを投稿