本記事では、CLIP Object Detection and Segmentationと呼ばれる機械学習手法を使って、画像中から入力したキーワードに適した物体を検出する方法を紹介します。

CLIP Object Detection and Segmentation(CLIP-ODS)
概要
CLIP ODSは、事前学習済みの視覚言語モデルCLIPを用いて、ゼロショットセマンティックセグメンテーションを実現する手法です。
CLIPとは、ImageToTextタスクを実現する手法で、画像を認識し適切なキャプション(画像の説明)を生成する技術です。
下図のように入力された画像の特徴から、対応する画像の説明をテキストで出力します。

CLIPは、他にもTextToImageタスクと呼ばれるテキストから画像を生成する技術などでも利用されており、CLIPをベースとした様々な手法が提案されています。
TextToImageの一例であるFuseDreamを下記の記事で紹介しているので宜しければご参照ください。
[FuseDream] AIを使ってテキストから絵を描く [日本語対応]
FuseDreamと呼ばれる機械学習手法を用いてAIにテキストを入力し画像を生成させる方法を紹介しています。
セマンティックセグメンテーションとは、画像中の全てのピクセルをクラスに分類することを指し、下図の例では「wheel of bicycle」や「face of dog」など入力テキストに対応したピクセル部分が図示されています。
 |
| 出典: https://github.com/shonenkov/CLIP-ODS |
また、CLIP ODSは以下のような構成で実現されています。
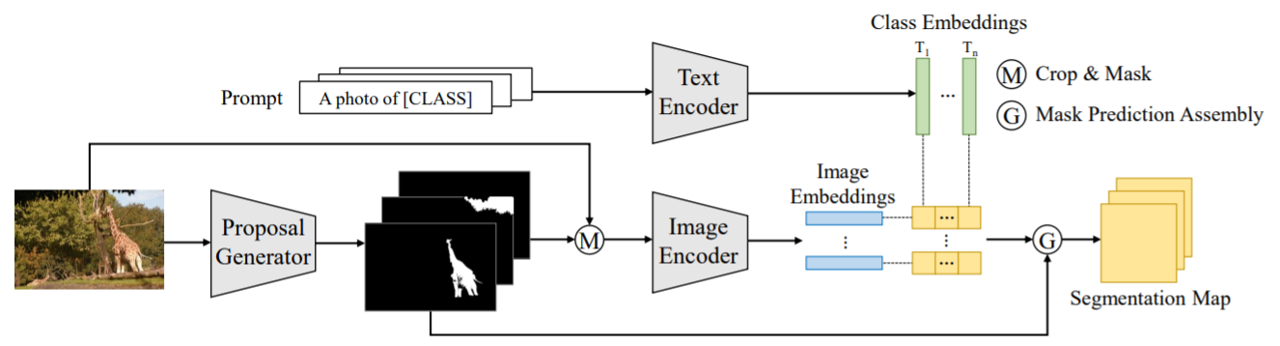
|
| 出典: https://arxiv.org/pdf/2112.14757.pdf |
簡単な理解としては、以下のとおりです。
-
入力画像からマスク画像(上図白黒画像)を生成
この時、画像中のオブジェクトをピクセル単位で全て分類 - CLIPを用いてマスク画像をCLASSに分類
- 入力されたテキストに近しいCLASSのマスク画像を選定
- 入力テキストに応じたセマンティックセグメンテーションを出力
デモ(Colaboratory)
それでは早速CLIP-ODSをGoogle Colaboratoryで動かしていきます。
なお、これから紹介するソースコードは全てこちらのGitHubに掲載しております。以下のボタンをクリックするとColaboratoryを開くことも可能です。
また、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
おすすめの書籍
[初心者向け] Pythonで機械学習を始めるまでに読んだおすすめ書籍一覧
本記事では、現役機械学習エンジニアとして働く筆者が実際に読んだ書籍の中でおすすめの書籍をレベル別に紹介しています。
おすすめのオンライン講座
[初心者向け] 機械学習がゼロから分かるおすすめオンライン講座
本記事では、機械学習エンジニアとして働く筆者が、AI・機械学習をまったく知らない方でも取り組みやすいおすすめのオンライン講座をご紹介しています。
環境セットアップ
まず、Pytorchや、その他ライブラリをインストールします。
上記ではColaboratoryにインストールされているCudaドライバーのバージョンを確認しています。
以降ではCudaドライバーに対応したPytorchをインストールします。
モデルのロード
次に、学習済みモデルをロードします。学習済みモデルはclip_odsライブラリを介して自動でダウンロードされます。
物体検出用画像の準備
uploadを選択するとPCからアップロードした画像を物体検出に使用します。
sampleを選択するとCLIP ODSライブラリ提供元から提供された画像をダウンロードして使用します。
本記事では、以下の画像を使用します。

セマンティックセグメンテーション
入力画像に対してセマンティックセグメンテーションを行います。
本記事では、「watch」を入力し、画像中から"時計"を検出してみます。
セマンティックセグメンテーションの結果は以下の通りです。

物体検出
セグメンテーションマスクをオフすることで、矩形のみを表示することもできます。
物体検出結果は以下の通りです。

検出精度にややずれがありますね。
下記は2022年にMeta(旧Facebook)が発表したDeticです。検出精度は最新なだけありかなりのものです。
[Detic] 最新の物体検出で画像検索 [Python]
本記事では、Meta(旧 Facebook)が発表したDetic(Detecting Twenty-thousand Classes using Image-level Supervision)を使用して任意の検索キーワードで物体検出を行う方法を紹介しています。
まとめ
本記事では、CLIP-ODSと呼ばれる機械学習手法を用いて、キーワードに応じたセマンティックセグメンテーションを行いました。
この技術の精度が向上すれば、膨大な写真の中からキーワードに対応する画像のみを切り出して出力するなんてことが可能になるかもしれません。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
機械学習について学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1. 論文 - A Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model






0 件のコメント :
コメントを投稿