In this article, I will introduce how to detect objects with arbitrary search keywords using Detic (Detecting Twenty-thousand Classes using Image-level Supervision) announced by Meta (formerly Facebook).

Detic
Abstract
Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning.
Below is an example of the image classification dataset ImageNet.

Below is an example of the object detection dataset LVIS.

feature
As shown in the above figure, the object detection dataset needs to be given the position information of the object to be detected in the image. For this reason, it is more costly to secure a data set for object detection than to classify images. Detic is now able to train object detection on image classification datasets, so it is learning a large number of objects from a large dataset. This makes it possible to detect more and more various objects than before. In addition, by incorporating CLIP, object detection suitable for any keyword is also realized.
demo(Colaboratory)
This chapter describes a demo by Google Colab.
In addition, all the implementations described below are posted here. To run it, please change runtime to GPU.
Setup environment
install detectron2 using pip.
then, code clone from GitHub
Setup environment is done.
Load model
Then load the model. I will download and use the trained model provided by facebook.
Object detection
Next, upload the image for object detection. You can upload one or more files.
This time, enter these 4 images.

Performs object detection. If you enter the name of the detected object in detect_target, the corresponding object will be detected. This time I will try to detect the laptop.
The detection results are as follows.




It has been detected quite accurately. Finally, load the vocabulary and try to detect everything that can be detected.
Load the vocabulary from the lvis dataset.
The detection results are as follows.


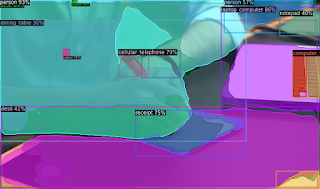
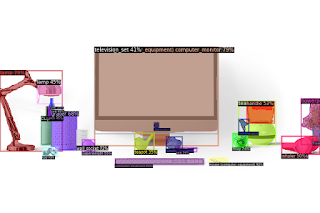
We can see that the object can be detected in very small detail.
Summary
In this article, I introduced how to use Detic to detect objects with arbitrary keywords. It is quite amazing to expand the conventional functions and improve the accuracy while making it easy to secure the data set. It's painful to actually create it, but annotating the object detection dataset is a painful task. Many people would be saved if Detic freed them from that task.
References
1. Paper - Detecting Twenty-thousand Classes using Image-level Supervision






0 件のコメント :
コメントを投稿