本記事では、OneFormerと呼ばれる機械学習手法を用いて、一つのモデルでpanoptic/instance/semantic segmentationを行う方法をご紹介します。
OneFormer
概要
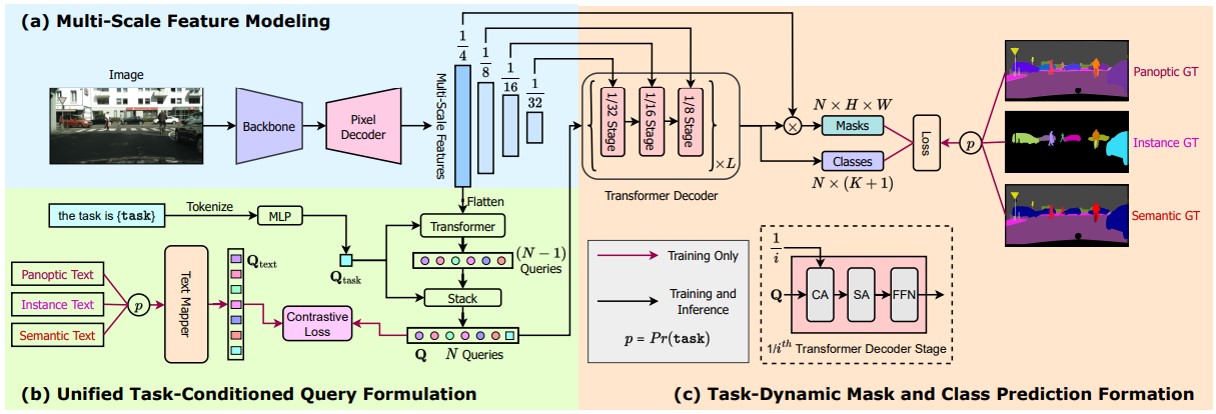
従来のセグメンテーション技術は、panoptic/instance/semantic segmentationのそれぞれのタスクで最高のパフォーマンスを実現するため、それぞれのモデルを個別にトレーニングする必要がありました。
OneFormerでは、この3つのセグメンテーションタスクを、1つのアーキテクチャと1回のトレーニングで実現するユニバーサルイメージセグメンテーションフレームワークです。
なお、それぞれのセグメンテーションタスクの違いについては以下の記事をご参照下さい。
検出クラスは2万越え! Deticを使って物体を検出しよう
本レシピでは、2022年にMeta(旧Facebook)が発表したDeitcの技術概要、Deticの動かし方などを紹介します。
トランスフォーマーベースのOneFormerでは、panopticアノテーションから全てのラベルを導出しマルチタスクをトレーニングすることによりsemanticなどのグラウンドトゥルースドメインを均一にサンプリングしています。
この構成により、COCOなどいくつかのデータセットでSOTAを達成しています。
詳細はこちらの論文をご参照ください。
本記事では上記手法を用いて、任意の画像のpanoptic/instance/semantic segmentationを行います。
デモ(Colaboratory)
それでは、実際に動かしながらセグメンテーションタスクを実行します。
ソースコードは本記事にも記載していますが、下記のGitHubでも取得可能です。
GitHub - Colaboratory demo
また、下記から直接Google Colaboratoryで開くこともできます。

なお、このデモはPythonで実装しています。
Pythonの実装に不安がある方、Pythonを使った機械学習について詳しく勉強したい方は、以下の書籍やオンライン講座などがおすすめです。
環境セットアップ
それではセットアップしていきます。
Colaboratoryを開いたら下記を設定しCPUを使用するようにしてください。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をCPUに変更
初めにGithubからソースコードを取得します。
%cd /content
!git clone https://github.com/SHI-Labs/OneFormer-Colab.git
# using Commits on Nov 18, 2022
%cd /content/OneFormer-Colab
!git checkout 08ae914313bd1ff4688eb5e58f7845760fd60643
%cd /content
!mv OneFormer-Colab OneFormer
次にライブラリをインストールします。
%cd /content/OneFormer
# install pytorch
!pip install torch==1.9.0 torchvision==0.10.0 --quiet
# install opencv
!pip install -U opencv-python --quiet
# install detectron2
!python -m pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu102/torch1.9/index.html --quiet
!pip3 install natten==0.14.2 -f https://shi-labs.com/natten/wheels/cu102/torch1.9/index.html --quiet
# install other
!pip install git+https://github.com/cocodataset/panopticapi.git --quiet
!pip install git+https://github.com/mcordts/cityscapesScripts.git --quiet
!pip install -r requirements.txt --quiet
!pip install ipython-autotime
!pip install imutils
最後にライブラリをインポートします。
%cd /content/OneFormer
# Setup detectron2 logger
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
setup_logger(name="oneformer")
# Import libraries
import numpy as np
import cv2
import torch
from google.colab.patches import cv2_imshow
import imutils
device = 'cuda' if torch.cuda.is_available() else "cpu"
print("using device is", device)
# Import detectron2 utilities
from detectron2.config import get_cfg
from detectron2.projects.deeplab import add_deeplab_config
from detectron2.data import MetadataCatalog
from demo.defaults import DefaultPredictor
from demo.visualizer import Visualizer, ColorMode
# import OneFormer Project
from oneformer import (
add_oneformer_config,
add_common_config,
add_swin_config,
add_dinat_config,
add_convnext_config,
)
以上で環境セットアップは完了です。
Helper関数の定義
モデルのロードや、タスク定義用のHelper関数を定義します。
SWIN_CFG_DICT = {
"cityscapes": "configs/cityscapes/oneformer_swin_large_IN21k_384_bs16_90k.yaml",
"coco": "configs/coco/oneformer_swin_large_IN21k_384_bs16_100ep.yaml",
"ade20k": "configs/ade20k/oneformer_swin_large_IN21k_384_bs16_160k.yaml"
}
DINAT_CFG_DICT = {
"cityscapes": "configs/cityscapes/oneformer_dinat_large_bs16_90k.yaml",
"coco": "configs/coco/oneformer_dinat_large_bs16_100ep.yaml",
"ade20k": "configs/ade20k/oneformer_dinat_large_IN21k_384_bs16_160k.yaml"
}
def setup_cfg(dataset, model_path, use_swin):
# load config from file and command-line arguments
cfg = get_cfg()
add_deeplab_config(cfg)
add_common_config(cfg)
add_swin_config(cfg)
add_dinat_config(cfg)
add_convnext_config(cfg)
add_oneformer_config(cfg)
if use_swin:
cfg_path = SWIN_CFG_DICT[dataset]
else:
cfg_path = DINAT_CFG_DICT[dataset]
cfg.merge_from_file(cfg_path)
cfg.MODEL.DEVICE = 'cpu'
cfg.MODEL.WEIGHTS = model_path
cfg.freeze()
return cfg
def setup_modules(dataset, model_path, use_swin):
cfg = setup_cfg(dataset, model_path, use_swin)
predictor = DefaultPredictor(cfg)
metadata = MetadataCatalog.get(
cfg.DATASETS.TEST_PANOPTIC[0] if len(cfg.DATASETS.TEST_PANOPTIC) else "__unused"
)
if 'cityscapes_fine_sem_seg_val' in cfg.DATASETS.TEST_PANOPTIC[0]:
from cityscapesscripts.helpers.labels import labels
stuff_colors = [k.color for k in labels if k.trainId != 255]
metadata = metadata.set(stuff_colors=stuff_colors)
return predictor, metadata
def panoptic_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "panoptic")
panoptic_seg, segments_info = predictions["panoptic_seg"]
out = visualizer.draw_panoptic_seg_predictions(
panoptic_seg.to(device), segments_info, alpha=0.5
)
return out
def instance_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "instance")
instances = predictions["instances"].to(device)
out = visualizer.draw_instance_predictions(predictions=instances, alpha=0.5)
return out
def semantic_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "semantic")
out = visualizer.draw_sem_seg(
predictions["sem_seg"].argmax(dim=0).to(device), alpha=0.5
)
return out
TASK_INFER = {
"panoptic": panoptic_run,
"instance": instance_run,
"semantic": semantic_run
}
学習済みモデルのセットアップ
ここでは、論文発表元が公開している学習済みモデルをGoogle Colaboratoryにダウンロードします。
以下では、ADE-20kデータセットでトレーニングされたbackborn DiNAT-Lを使用したモデルをダウンロードしています。
%cd /content/OneFormer
!mkdir pretrained
use_swin = False
if use_swin == False:
# download wight, backborn: DiNAT-L, ADE20k dataset
!wget -c https://shi-labs.com/projects/oneformer/ade20k/250_16_dinat_l_oneformer_ade20k_160k.pth \
-O pretrained/250_16_dinat_l_oneformer_ade20k_160k.pth
# init modules
predictor, metadata = setup_modules("ade20k", "pretrained/250_16_dinat_l_oneformer_ade20k_160k.pth", use_swin)
else:
# download wight, backborn: Swin-L, ADE20k dataset
!wget -c https://shi-labs.com/projects/oneformer/ade20k/250_16_swin_l_oneformer_ade20k_160k.pth \
-O pretrained/250_16_swin_l_oneformer_ade20k_160k.pth
# init modules
predictor, metadata = setup_modules("ade20k", "pretrained/250_16_swin_l_oneformer_ade20k_160k.pth", use_swin)
テスト画像のセットアップ
ここでは、モデルに入力する画像をWeb上から取得します。
%cd /content/OneFormer
!mkdir input_img
!wget -c https://www.pakutaso.com/shared/img/thumb/YAT4M3A7518_TP_V.jpg \
-O input_img/test01.jpg
img = cv2.imread("input_img/test01.jpg")
img = imutils.resize(img, width=640)
cv2_imshow(img)
以下の画像を使用します。
panoptic segmentation
それでは、panoptic segmentationを実行します。
# setup task
task = "panoptic"
# inference
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
# show result
cv2_imshow(out[:, :, ::-1])
出力結果は以下の通りです。
任意の画像に対しても良好な精度で検出できています。
instance segmentation
続いて、instance segmentatiaonを実行します。
先ほどと同じモデルに対してtaskを切り替えるのみで実行可能です。
# setup task
task = "instance"
# inference
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
# show result
cv2_imshow(out[:, :, ::-1])
出力結果は以下の通りです。
semantic segmentation
最後にsemantic segmentationを実行します。
# setup task
task = "semantic"
# inference
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
# show result
cv2_imshow(out[:, :, ::-1])
出力結果は以下の通りです。
モデル一つで、それぞれのタスクを切り替えられることが確認できます。
まとめ
本記事では、OneFormerを用いてpanoptic/instance/semantic segmentationを行う方法を紹介しました。
モデルを一本化できることで、トレーニング時間を削減でき、モデルの管理も容易になるため、社会実装向け技術であるように思います。
また本記事では、機械学習を動かすことにフォーカスしてご紹介しました。
もう少し学術的に体系立てて学びたいという方には以下の書籍などがお勧めです。ぜひご一読下さい。
リンク
リンク
また動かせるだけから理解して応用できるエンジニアの足掛かりに下記のUdemyなどもお勧めです。
参考文献
1.
論文 - OneFormer: One Transformer to Rule Universal Image Segmentation
2. GitHub - SHI-Labs/OneFormer












0 件のコメント :
コメントを投稿